

LangChain에서 Arxiv 논문 문서를 바로 불러올 수 있는 사실!
우선 관련 라이브러리를 설치해 주어야 합니다.
pip install -qU arxiv
아카이브 라이브러리 자체가 존재하는지를 몰랐네요...
https://pypi.org/project/arxiv/
arxiv
Python wrapper for the arXiv API: https://arxiv.org/help/api/
pypi.org
해당 라이브러리를 통해 Arxiv 논문을 pdf 파일로 바로 다운로드 받을 수도 있고, API를 호출할 수도 있습니다.
특정 키워드에 대한 검색도 가능합니다.

query에 특정 값을 입력해줌으로써
관련 키워드를 가진 논문을 추출해 낼 수 있습니다.
다음으로는, arxiv.org에서 라이브러리를 통해 다운로드 한 pdf 파일을 텍스트 형식으로 변화는 PyMuPDF 파이썬 패키지를 설치해야 합니다.
pip install -qU pymupdf랭체인에서 Arxivloader import 하기
랭체인에서 Arxiv loader를 이용해 Arxiv에 있는 데이터를 불러오기 위해서는 아래와 같이 로드해주면 됩니다.
from langchain_community.documents_loaders import ArxivLoader
Arxivloader 에서 입력으로 넣어줄 수 있는 파라미터는 아래와 같습니다.
- query = Arxiv 에서 문서를 찾는데 사용되는 텍스트 (키워드가 될 수 도 있고, 발행 id 넘버가 될 수 도 있음.)
- load_max_docs = 다운로드할 문서의 수를 제한하는 데 사용됨 (기본 값 : 100개)
- load_all_available_meta = 기본적으로 중요한 메타정보들이 다운로드됨. (Title, Authors, Summary) (기본 값 : False)
랭체인 ArxivRetriever
랭체인 ArxivRetriever 모듈을 통해 쓸 수 있는 파라미터는 아래와 같습니다.
- load_max_docs
- load_all_available_meta (Title, Authors, Summary)
- get_relevant_documents() (query)
Retrieval는 말 그대로 검색기이죠? 랭체인과 논문검색 API를 이용해서 논문에 있는 내용을 검색해서 데이터로 사용할 수 있는 모듈입니다.
먼저 Retriever를 실행하는 방법은 아래와 같습니다.
# 필요 모듈 import
from langchain_community.retrievers import ArxivRetriever
# load_max_docs = 2로 줌으로써 2개의 문서 불러오기
retriever = ArxivRetriever(load_max_docs = 2)
docs = retriever.get_relevant_documents(query="Attention")
# 처음으로 나온 문서 확인
docs[0].metadata
#
docs[0].page_content[:400]
저는 "Attention Machanism" 키워드를 이용한 논문 검색을 진행해보았습니다.
load_max_docs 를 3으로 놓고 3가지 키워드를 뽑아 보았더니 아래와 같이 출력됩니다.
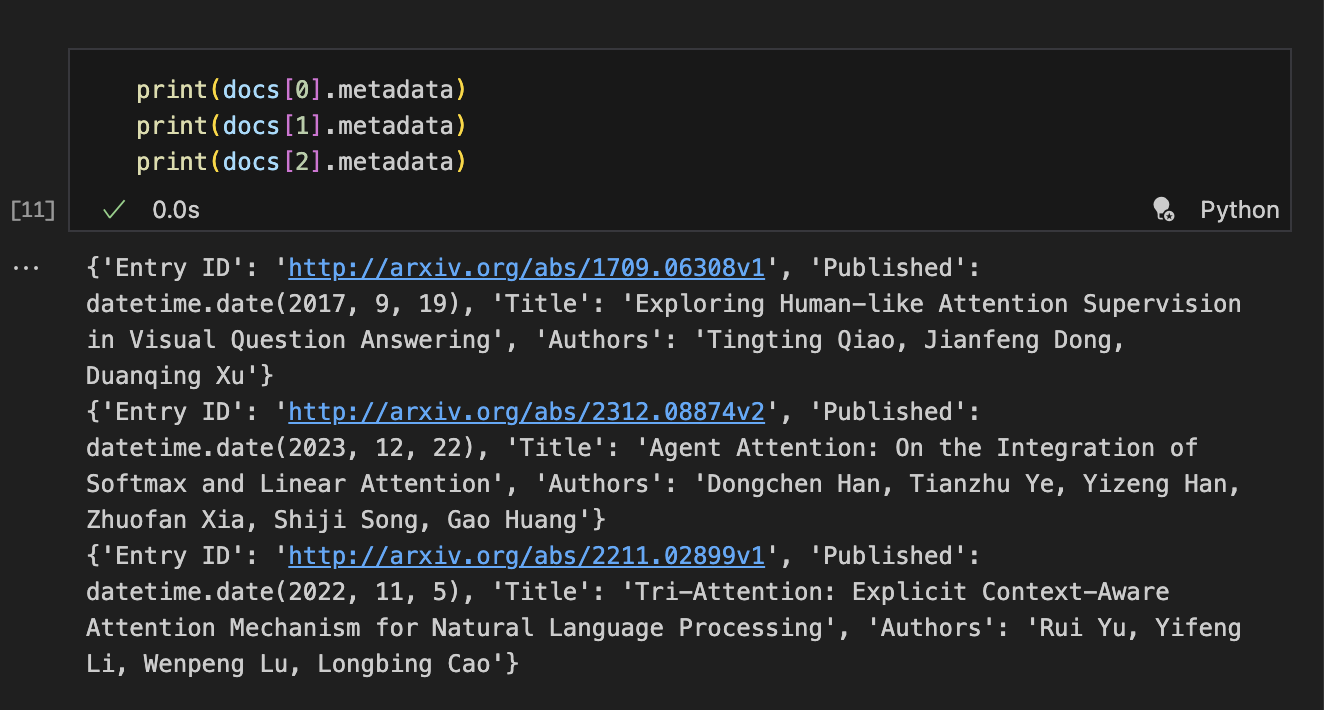
Arxiv를 통해 이렇게 불러온 논문 정보들을 바탕으로 LangChian의 chain을 이용하여 질문을 기반으로 QA를 하는 실습을 진행해 봅시다.
먼저 OpenAI API KEY를 import 해 줍니다.
import os
from dotenv import load_dotenv, find_dotdenv
load_dotenv(find_dotenv(), override = True)
Chain과 Model을 import 해 줍니다.
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo") # 'gpt-4-turbo'를 이용해도 됩니다.
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
위에서 불러온 Chain과 Model 을 바탕으로 아래와 같이 질문 query 를 작성합니다.
questions = [
"What is the Attention Machanism??",
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result["answer"]))
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
다음과 같이 Arxiv 검색한 내용을 바탕으로 답변을 작성해주는 것을 확인할 수 있습니다.
'LLM > LangChain' 카테고리의 다른 글
| LangChain, Chromadb 이용 문서 기반 RAG 구현하기 (0) | 2024.04.04 |
|---|---|
| OpenAI API Key 발급 및 환경변수에 관리하기 + colab 에서 사용하기 (0) | 2024.03.06 |
| [LangChain for LLM Application Development] 랭체인 Agent (0) | 2024.02.03 |
| [LangChain for LLM Application Development] 랭체인 Evaluation (0) | 2024.02.03 |
| [LangChain for LLM Application Development] 랭체인 QA (1) | 2024.02.03 |