

본 게시물은 Deeplearning.ai 코스를 수강 후 요약 및 정리한 내용입니다.
LLM task에서 중요한 부분 또 한가지!
대규모 언어모델을 통해 챗봇을 만들고 이를 기반으로 사용자와 모델 간 대화를 하기 위해서는 언어 모델이 사용자의 입력을 기억하고 그에 맞는 답변을 도출해야 한다!
이를 Memory라고 하는데, 더 많은 대화 내용을 기억하고 있을 수록 더 구체적이고 정확한 답변이 가능해 질 것이고, 반대로 많은 내용을 기억하다 보면 다양한 LLM 모델들은 보통 토큰 단위로 요금을 지불하기 때문에 너무 많은 내용을 기억하면 토큰 비용이 증가하게 될 것이다.
그래서 이 메모리를 효율적으로 관리하는 것이 가장 중요할 것으로 생각되는데, LangChain에서는 이 메모리들을 관리할 수 있는 기본적인 모듈들을 제공한다!
사실 정확히 LLM 모델이 대화 상태 자체를 기억하고 보존하는 것은 아니다!
(각 트랜젝션과 API 엔드포인트 호출은 독립적이기 때문에)
따라서 챗봇이 메모리를 가지고 있는 것 처럼 보이는 이유는
보통 코드로 지금까지의 대화내용을 전부 아주 빠르게 다시 LLM input 맥락으로 제공하고 있기 때문이다!!
https://python.langchain.com/docs/modules/memory/types/
Memory types | 🦜️🔗 Langchain
There are many different types of memory.
python.langchain.com
메모리 사용해보기

LangChain 모듈에서 메모리를 사용하기 위해, 다음과 같이 모델 종류를 지정해주고 (모델 종류를 지정해주는 이유는 모델마다 토큰을 계산하는 방법이 다르기 때문이다! - 후에 다른 게시물에서 설명하도록 함) 메모리를 지정해준다.
위 그림에선 ConversationBufferMemory를 지정해주었다.
세부 내용으로 verbose = True로 하게 되면 모델이 어떻게 기억하고 있는지를 아래와 같은 그림으로 보여준다.
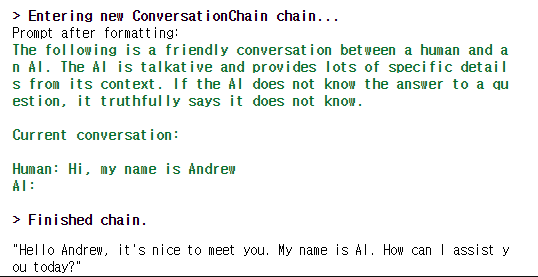
이를 보고싶지 않다면 verbose = False로 지정해두면 된다. ㅎㅎ
메모리 버퍼를 이용하여 출력을 저장하였기 대문에 이를 다시 출력 해 보면 그동안 나눈 대화 내용의 기록을 확인할 수 있다.


강의에서 설명하는 LangChain 프레임워크가 제공하는 memory 종류는 아래와 같다. 물론 더 많은 메모리들을 제공하고 있으니 공식 문서를 활용하여 필요한 메모리를 찾아 쓰는 것도 좋다!
- Conversation Buffer Memory
- Conversation Buffer Window Memory
- Conversation Token Buffer Memory
- Conversation Summary Memory
이렇게 대표적인 4개 메모리만 우선 설명해보도록 하겠다.
Conversation Buffer Memory
기본적인 Conversation Buffer Memory는 위의 예시에서 쓰인 것처럼 사용자와 나눈 모든 대화를 저장한다.
그 후, 저장한 메세지를 Prompt input variable로 입력한다.

또한 다음과 같이 기억해야 할 내용들을 더 추가할 수도 있다.
Conversation Buffer Window Memory
Conversation Buffer Window Memory는 메모리의 윈도우만 보존하는 메모리를 말한다. 여기서 의미하는 윈도우는 대화창을 의미하는 것으로 보인다!

Conversation Buffer Window Memory는 다음과 같이 사용하는데, 여기서 지정하는 K는 몇 턴의 대화를 기억하고 싶은지를 설정할 파라미터이다. (한 턴 : 사용자의 말 하마디와 챗봇의 말 한마디)
위 그림에서는 K값을 1로 지정해주었으므로, 마지막으로 답변한 한 턴의 대화만 저장하고 싶다는 것을 의미한다.

memory.load_memory_variables({})
코드를 이용하여 결과물을 출력한 결과, Memory를 통해 기억하고 있는 변수들이 마지막 턴만을 저장하고 있는 것을 확인할 수 있다!

Conversation Token Buffer Memory
Conversation Token Buffer Memory의 경우는 저장할 토큰의 수를 제한한다.
앞서 말했듯, 보통 LLM의 비용은 토큰의 수에 따라 책정이 되는데 LLM 호출 비용에 있어 더 효율적으로 관리할 필요성이 있을때 이 메모리를 사용한다!

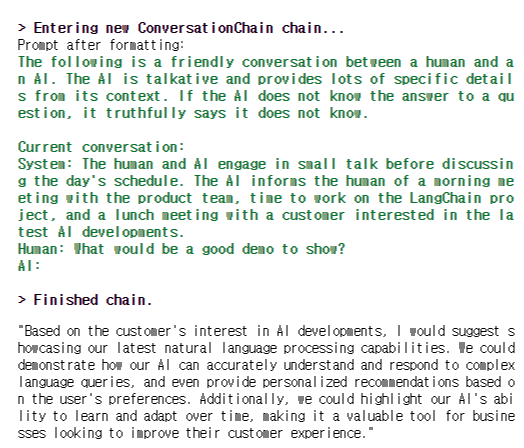
다음 이미지처럼, 토큰 한도를 초과하지 않기 위해 대화의 이전 부분은 삭제하고 가장 최근 대화 턴만 가져와서 한도 이내로 맞추게 된다.
Conversation Summary Memory
Conversation Summary memory의 경우 최근 발언의 토큰 개수나 대화 턴을 고정해 놓지 말고, 아예 지금까지의 대화내용을 요약하는 LLM을 사용해서 그 요약 내용을 메모리로 이용하는 것이다!
CSBM의 경우 명시적으로 저장하는 메세지의 크기를 앞서 정한 최대 토큰 수 한도 내로 맞추려 할 것이고 이에 따라 명시적 저장 공간은 요청한 토큰 수 대로 제한 될 것이며 이 한도를 넘어가면 CLM을 사용해 요약글을 만들어 낼 것이다!
추가로 다양한 메모리들이 존재하니
앞서 링크한 LangChain 공식 문서를 참고하면 좋을 것 같다!
'LLM > LangChain' 카테고리의 다른 글
| [LangChain for LLM Application Development] 랭체인 Agent (0) | 2024.02.03 |
|---|---|
| [LangChain for LLM Application Development] 랭체인 Evaluation (0) | 2024.02.03 |
| [LangChain for LLM Application Development] 랭체인 QA (1) | 2024.02.03 |
| [LangChain for LLM Application Development] 랭체인 Chains (1) | 2023.12.20 |
| [LangChain for LLM Application Development] 랭체인 Models, Prompts and Parsers (0) | 2023.12.15 |