

https://github.com/architectyou/prompt-tester.git
GitHub - architectyou/prompt-tester: A local LLM prompt testing tool inspired by LangSmith playground. Built with streamlit, thi
A local LLM prompt testing tool inspired by LangSmith playground. Built with streamlit, this tool allows you to compare two different prompt versions or test a single prompt multiple times. - archi...
github.com
왜 랭스미스를 안쓰고...?
랭체인을 주로 사용하시는 분들이라면,
아마도 랭스미스나 openai의 playground 서비스를 주로 사용하실 듯 합니다.
그런데 로컬 모델로 프롬프트를 작성하면 playground 서비스를 이용하기 어렵다는 한계점이 있는데요,
그래서 cursorAI와 함께 간단하게 Prompt Tester를 제작해보았습니다🙌

랭스미스의 좋은 기능 중 하나가 바로 이렇게 Playground를 제공한다는 것인데요,

위 그림과 같이 모델이나 프롬프트 설정을 바꿔보며 프롬프트 A/B 테스트를 진행하고 적용해 볼 수 있습니다.

하지만 다음과 같이 LangChain에서 공식적으로 제공하는 모델들은 한계가 있습니다.
물론 Custom 모델 칸도 존재하긴 하는데요,

특정 모델에 대한 Base URL을 어떻게 설정해야 할지 나와있지 않아서 🥲
적용하기가 생각보다 어렵더라구요.
OpenAI의 ChatComplete 포맷을 사용하는 sglang을 이용해서 서빙했음에도 불구하고 URL 을 통한 모델 호출이 잘 안됐습니다😑
하지만,
로컬 모델의 프롬프팅이 더 어려운법...
Streamlit으로 간단하게 해당 UI에 맞춰 작업을 진행하고,
필요한 파라미터 값들을 입력해서 프롬프트 A/B 테스트를 진행 해 볼 수 있도록 내가 필요하니까 만들자! 하며 개발을 진행해 보았습니다.
Prompt A/B Tester 제작하기
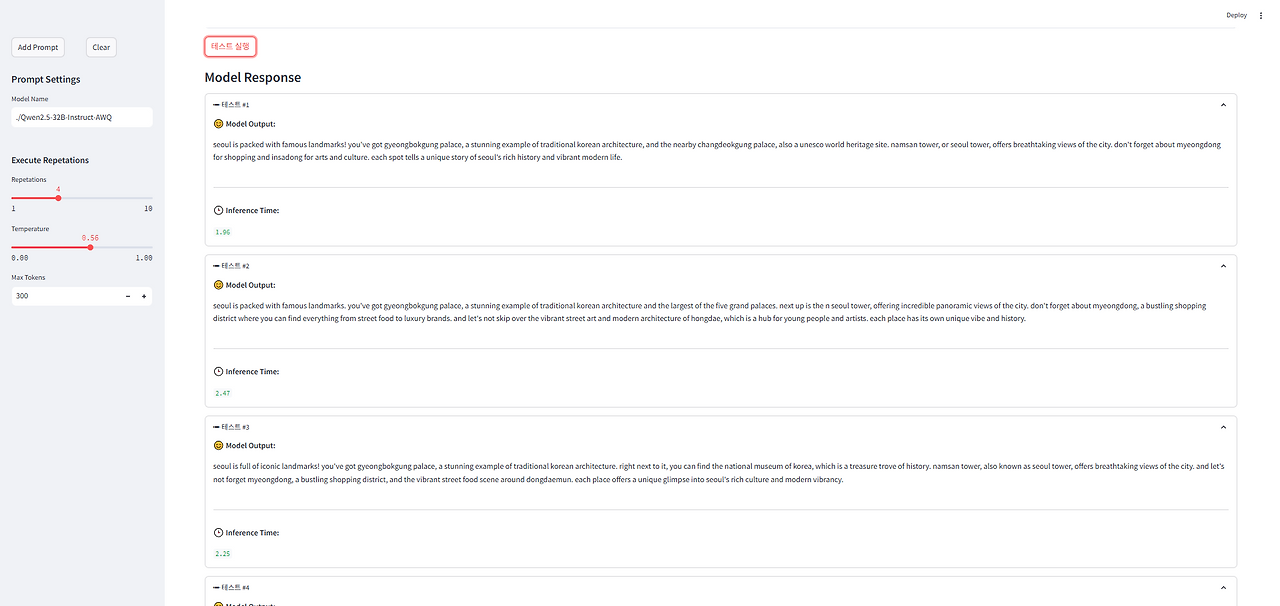
모델에 대한 설정 값을 항상 조절하면서 사용하기 때문에
20번의 생성모델을 돌린다고 해도 항상 20번의 같은 답이 나오지는 않습니다.
따라서 횟수를 조정해서 모델을 여러 번 호출 할 수 있도록 지정해주었습니다.
모든 파라미터 값들은 Streamlit의 기본 기능들을 이용해 구성하였으며,
LLM 호출은 아래 클래스를 지정하여 설정해주었습니다.
class LLMResponse:
"""
LLM_Response class, define the llm client
"""
def __init__(self):
self.client = AsyncOpenAI(
base_url=os.getenv("BASE_URL"), # LLM server url. if you use OpenAI API, you can leave it blank.
api_key=os.getenv("API_KEY") # LLM server api key
)
async def model_completion(self, model_name, system_prompt, human_prompt, temperature, max_tokens=300):
start_time = time()
response = await self.client.chat.completions.create(
model = model_name,
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": human_prompt}
],
temperature=temperature,
max_tokens=max_tokens,
)
get_response = response.choices[0].message.content.strip().lower()
end_time = time()
inference_time = round(end_time - start_time, 2)
return get_response, inference_time
랭스미스에서 한 가지의 프롬프트를 20회 이상 돌려 결과물을 비교해보기도 하지만,
이전의 프롬프트와 새로 고친 프롬프트를 비교하여 (프롬프트 버전화) 프롬프트 수정을 진행하기도 합니다.
따라서 이전 버전과 고친 버전의 응답을 비교하기 위해 Column을 두 개로 나누고 프롬프팅 비교 로직을 작성하였습니다.
def main(self):
if st.session_state['compare_prompts']:
with st.sidebar :
st.header("")
st.subheader("Comparing Prompt Models")
prompt1_model = st.text_input("Prompt1 Model name", value="./Qwen2.5-32B-Instruct-AWQ")
prompt2_model = st.text_input("Prompt2 Model name", value="./Qwen2.5-32B-Instruct-AWQ")
print(st.session_state)
col1, col2 = st.columns(2)
with col1:
st.markdown("**Prompt Set 1**")
system_prompt1 = st.text_area(
"SYSTEM 1",
value=st.session_state.system_prompt1_saved or st.session_state.system_prompt_saved,
height=68,
placeholder="Write the System Prompt...",
key="system_prompt1"
)
st.session_state.system_prompt1_saved = system_prompt1
human_prompt1 = st.text_area(
"HUMAN 1",
value=st.session_state.human_prompt1_saved or st.session_state.human_prompt_saved,
height=300,
placeholder="Write the Human Prompt...",
key="human_prompt1"
)
st.session_state.human_prompt1_saved = human_prompt1
with col2:
st.markdown("**Prompt Set 2**")
system_prompt2 = st.text_area(
"SYSTEM 2",
value=st.session_state.system_prompt2_saved or st.session_state.system_prompt_saved,
height=68,
placeholder="Write the System Prompt...",
key="system_prompt2"
)
st.session_state.system_prompt2_saved = system_prompt2
human_prompt2 = st.text_area(
"HUMAN 2",
value=st.session_state.human_prompt2_saved or st.session_state.human_prompt_saved, # 저장된 값 사용
height=300,
placeholder="Write the Human Prompt...",
key="human_prompt2"
)
st.session_state.human_prompt2_saved = human_prompt2
if st.button("테스트 실행", key="run_test_double"):
if not (system_prompt1 and human_prompt1) or not (system_prompt2 and human_prompt2):
st.warning("프롬프트를 모두 입력해주세요.")
return
다음과 같이 프롬프트 로직을 비교해서 볼 수 있습니다.

후기
위 프롬프트 비교 로직을 통해
랭스미스나 OpenAI의 플레이그라운드를 사용하지 않아도
서빙 중인 로컬 모델들의 프롬프트 로직을 비교해 볼 수 있습니다. (OpenAI 형식으로 LLM을 지정하였기 때문에 OpenAI 모델들 역시 지원합니다.)
프롬프트 로직을 작성해 보면서 프롬프트 또한
코드 처럼 형상관리가 꼭 필요해 보인다는 생각이 듭니다..!
모든 소스코드는 맨 위 Github 링크에 업로드되어 있으니 참고하시면 좋겠습니다!
'LLM > PlayGround' 카테고리의 다른 글
| [MCP Tutorial] 01. MCP란? (1) | 2025.07.14 |
|---|---|
| [Ollama] Ollama hub 에 튜닝한 모델 push 하기 (Ollama push) (0) | 2025.01.03 |
| Gemma2-ko-9B Model 법률 데이터셋 Law-QA-Dataset Fine tuning 파인 튜닝 (2) | 2024.09.30 |