

안녕하세요, 이번에 리뷰해 본 논문은 25년 5월 발표된 From tokens to thoughts 라는 논문입니다.🤗
최근 Embedding 논문들에 관심을 가지면서 몇 가지 Embedding 관련 논문들을 읽어보았는데요, 모델이 표현하는 토큰/ 단어/ 문장의 의미와 인간이 표현하는 개념들에 대해서 어떤 차이가 있는지, 만약 차이가 존재한다면 우리가 앞으로 어떤식으로 모델들을 개발시켜야 하는지 그런 방향성에 대해서 고민해보는 논문입니다.
해당 개념을 표현하기 위해 인지과학적인 내용들도 좀 등장하는데요,
이런 식으로도 생각해 볼 수 있구나 정도로 편하게 읽어내려가 보았습니다.
원문은 아래 링크에서 확인하실 수 있습니다.
https://arxiv.org/abs/2505.17117
From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
Humans organize knowledge into compact categories through semantic compression by mapping diverse instances to abstract representations while preserving meaning (e.g., robin and blue jay are both birds; most birds can fly). These concepts reflect a trade-o
arxiv.org
Motivation
해당 논문의 요지와 동기는 다음과 같습니다. 지금까지 발전해온 LLM이 인간과 유사하게 개념과 의미를 정말로 이해하는지? 아니면 우리가 모델이 사람처럼 이해한다고 하는 부분이 단순히 데이터셋에 대한 정교적 통계적 패턴 매칭에만 기반하는지?에 대한 의문을 풀고자 합니다.
만약 단순히 정교적인 통계적 패턴 매칭에만 기반한다고 하면, LLM이 단순한 피상적 모방을 넘어 인간적인 이해를 하기 위해서는 LLM의 Representation이 정보압축(Compression)과 의미 보존(Semantic Fidelity)이라는 결정적인 Trade-off를 어떻게 다루는지를 조사하는 것이 중요할 것입니다.
따라서 본 연구에서는 Human Cognition 데이터셋과 Information Theory 이론들을 이용해 인간과 LLM의 개념 표현에 대해서 압축과 의미보존 사이의 Trade-off 관계를 정보이론적으로 분석합니다.
Research Questions
본 연구에서는 메인 질문 3가지를 바탕으로 매 챕터마다 3가지 질문에 대한 실험을 진행하고 결과를 해석하는 과정을 거칩니다.
가장 큰 메인 질문 3가지는 아래와 같습니다.
- [RQ1] 대규모 언어 모델 (LLMs)에서 나타나는 개념들은 사람이 정의한 개념 범주들과 어느정도 일치하는가?
- LLM이 학습 중에 자발적으로 형성한 의미구조 (Cluster)가 심리학적, 철학적, 언어학적으로 정의된 인간의 개념 체계와 유사한지?
- LLM의 Compression이 얼마나 잘 Clustering 되는지?
- [RQ2] LLM과 인간은 이러한 개념들 사이에서, 특히 항목의 전형성(Item Typicality)에 관해 유사한 내부 기하학적 구조를 보이는가?
- LLM의 개념공간 내부에 있는 점들간의 거리, 공간(Geometry)가 인간의 개념적 판단 구조와 유사한지?
- [RQ3] 인간과 LLM은 개념을 형성할 때 표현(Compression)과 의미적 충실도 (Semantic Fidelity) 사이의 균형을 맞추는 전략에서 어떻게 다른가?
연구의 메인 Research Question은 아마 3번째 질문이 되지 않을까 싶습니다. 두 개념형성 방법의 차이를 파악하고 어떻게 모델이 사람저럼 표현할 수 있을지에 대한 방향에 대한 고민을 제안합니다. 그래서 첫 번째 질문이 의미하는 것은 LLM 자체만 보고 판단했을때 표현을 잘 군집화 시켜서 의미가 유사한것들끼리 정말 유사한 의미공간상에 나타내는지를 평가합니다. 그리고 이런 군집들이 사람이 생각하는 개념체계과 유사하게 동작하는지를 판단합니다.
두 번째 질문에서는 LLM과 사람이 표현한 개념들이 비슷한 기하구조를 지니는지를 판단합니다. 특히 "전형성"이라는 내용에 집중하여 평가를 진행하는데요, 자연적인 개념은 명확한 경계 없이 어떤 항목이 그 범주에 속하는지가 굉장히 모호하게 결정됩니다. 예를들어 3가지 종류의 새 (ex. 참새, 박쥐, 펭귄)을 생각해본다면 날개가 있고 날아다니는 모양을 비추어 보아 모델은 참새와 박쥐를 좀 더 "Bird"라는 카테고리 안에 가두지만, 사실상 사람이 생각하기엔 펭귄은 날지 못해도 참새와 박쥐는 "조류"로 분류되고 오히려 박쥐는 "포유류"에 분류되는 것 처럼 말이죠. 이런 내용들을 고려했을 때, LLM과 사람이 표현한 개념들은 비슷한 기하 구조를 지니고 있을까?를 실험합니다.
세 번째 질문에서는 위의 두 질문 내용을 기반으로 정보이론적 개념을 접목시켜 표현(Compression)과 의미 보존(Semantic Fidelity)에 대한 Trade-off 관계를 측정합니다.
따라서 이런 내용들을 평가하기 위해 논문에서 사용된 정보이론적 접근은 LLM을 평가하는데 쓰이는 것 뿐 아니라 어떻게 인공지능과 자연지능(사람) 사이에서 Meaningful Representation을 나타내는지 이해하기 위해 사용됩니다.
Reference
앞서 설명한 것 처럼, 해당 논문에서는 위의 3가지 메인 질문들에 대한 실험을 위해 정보이론적 관점을 도입합니다. 대표적으로 등장하는 개념이 RDT(Rate-Distortion Theory)와 IB(Information Bottleneck)인데요, 내용은 아래와 같습니다.
- Rate-Distortion Theory
- 손실압축 정보이론의 주요 내용
- 압축(Compression)을 할 때 "정보를 얼마나 버려도 괜찮은가?"를 나타냄
- 정보를 손실압축 할 때, 주어진 허용 왜곡(Distortion) 수준에서 필요한 최소 비트수를 계산하는 이론
- Rate(표현 복잡도)와 Distortion(손실 왜곡)에 대해 설명
- Information Bottleneck
- Accuracy & Complexity 사이에서의 Best Trade-off를 찾기 위해 고안됨
- 입력과의 정보는 최소화하고 출력과의 정보는 최대화해서 필요한 정보만 압축해서 최대한 의미 있는 정보를 유지하고자 하는 내용
Benchmarking Against Human Cognition
시험을 위해 인간 범주화를 표현하기 위해 어떤 인간인지 심리학 데이터들을 사용했는지에 대해 설명합니다.
3가지 종류의 데이터셋을 사용했으며 인지과학 전문가들에게 꼼꼼하게 큐레이팅된 데이터셋을 사용합니다.
- Rosch (1973) : 전형적인 특징으로 Clustering 되어있는 데이터
- Rosch (1975) : 좀 더 큰 범주에 걸쳐, 더 큰 세트에 대한 광범위한 전형성 등급 제공
- McCloskey & Glucksbreg (1978) : Fuzzy boundaries of natural categories (자연 개념에서 모호한 경계에 해당하는 개념들)
Framework for comparing compression and meaning
해당 챕터에서는 LLM과 Human cognition의 기초적인 Representation에 대한 이해를 위해 Information Theorical Framework (정보이론적 관점의 프레임워크)를 사용합니다. 해당 챕터에서도 앞선 3가지 메인 질문에 기반한 Research question을 이용해 연구를 진행하게 됩니다.
- [RQ1] Probing Representational Compactness via Categorical Alignment (카테고리 정렬을 통한 표현의 압축성 탐색)
- AMI(Adjusted Mutual Information) 지표를 사용합니다.
- [RQ2] Probing Semantic Preservation via Internal Structure (내부 구조를 통한 Semantic Preservation 탐색)
- Distortion 이용
- [RQ3] Evaluating the integrated Trade-off for Total Representational Efficiency (전체 표현 효율성을 위한 통합된 트레이드 오프 평가)
- Unified Object Function 사용
따라서 위 세 가지 질문에 대해 앞서 설명한 RDT & IB Principle을 이용한 새로운 공식 (Objective function)을 제안합니다.
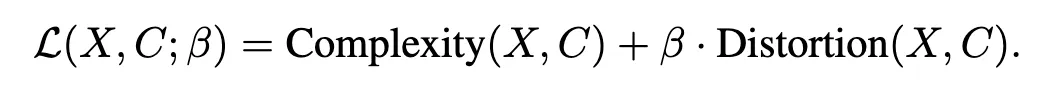
여기서 각 Complexity, Distortion은 아래 의미를 지닙니다.
- Complexity : 원본 항목 X를 군집 C에 표현할 때 informational cost 또는 복잡성을 측정하는 지표
- Distortion : 항목들을 클러스터로 묶는 과정에서 발생하는 의미 충실도 (Semantic Fidelity)의 손실을 정량화 한 것
먼저 복잡도는 다음과 같이 나타내집니다.

우변의 두번째 항은 각 군집 안에서 샘플을 식별하는데 필요한 평균 비트 수를 나타내며, 첫 번째 항은 전체 데이터 $X$를 식별하는 데 필요한 비트수를 나타냅니다. 따라서 이를 통해 데이터를 군집으로 압축했을 때 얼마나 정보가 절약(혹은 손실)되었는지를 정량화 할 수 있습니다.
의미 손실 정도는 다음과 같이 나타내집니다.
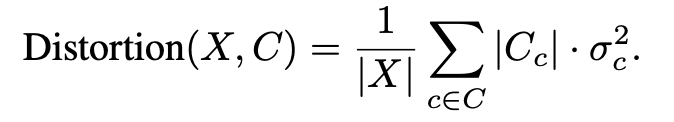
수식의 의미는 다음과 같습니다. 모든 클러스터에서 분산을 평균내어, 데이터가 군집 안에서 얼마나 흩어져있는지를 측정하는 수식입니다. 따라서 클러스터 안의 데이터가 잘 모여있다면 왜곡이 적다는 뜻이 되고, 데이터가 클러스터 안에서 멀리 퍼져있다면 왜곡이 크다는 뜻이 됩니다. 따라서 데이터를 클러스터의 Centroid로 대신할 때, 얼마나 의미를 잃었는지 (왜곡되었는지) 판단할 수 있습니다.
Unpacking Representational Strategies : An Empirical Investigation
해당 챕터에서도 역시 3가지 Research Question 관점에서 논문을 이어나갑니다.
- [RQ1] Assessing Conceptual Alignment to investigate how LLM-derived conceptual categories align with human-defined ones
- [RQ2] Examing Internal Cluster Geometry and Semantic Preservation to access how LLM representations capture human-like typicality
- [RQ3] Evaluating the Efficiency of the Compression-Meaning Trade-off to evaluate the overall balance of compression and meaning
해당 실험에서는 한가지 Encoder 기반 모델 (ex. BERT Family model)과 5가지의 Decoder based 모델을 사용했습니다. (ex. Gemma, Qwen, Phi, Llama, Mistral 모델) 구조가 다른 모델들을 사용해 실험해보았던 것도 꽤 눈여겨 볼 만한 포인트인데요, 우선 실험 결과를 함께 확인해보시죠.
[RQ1]
먼저 첫 번째 질문입니다.
인간이 정한 카테고리와 LLM이 클러스터링하는 카테고리가 얼마나 일치하는지를 확인합니다.
본 실험에서는, K-means 방식을 이용해서 LLM embedding clustering을 진행합니다. 이 때의 k 개수는 사람의 카테고리 개수와 일치시킵니다. 평가 정량지표로서 AMI, NMI, ARI 지표를 사용하는데, 대부분 정보이론 관점에서 볼 수 있던 평가지표 인 것 같습니다.
대략적으로 그 의미만 파악해보자면, AMI가 1에 가까울수록 두 군집이 유사하다는 것을 의미합니다.
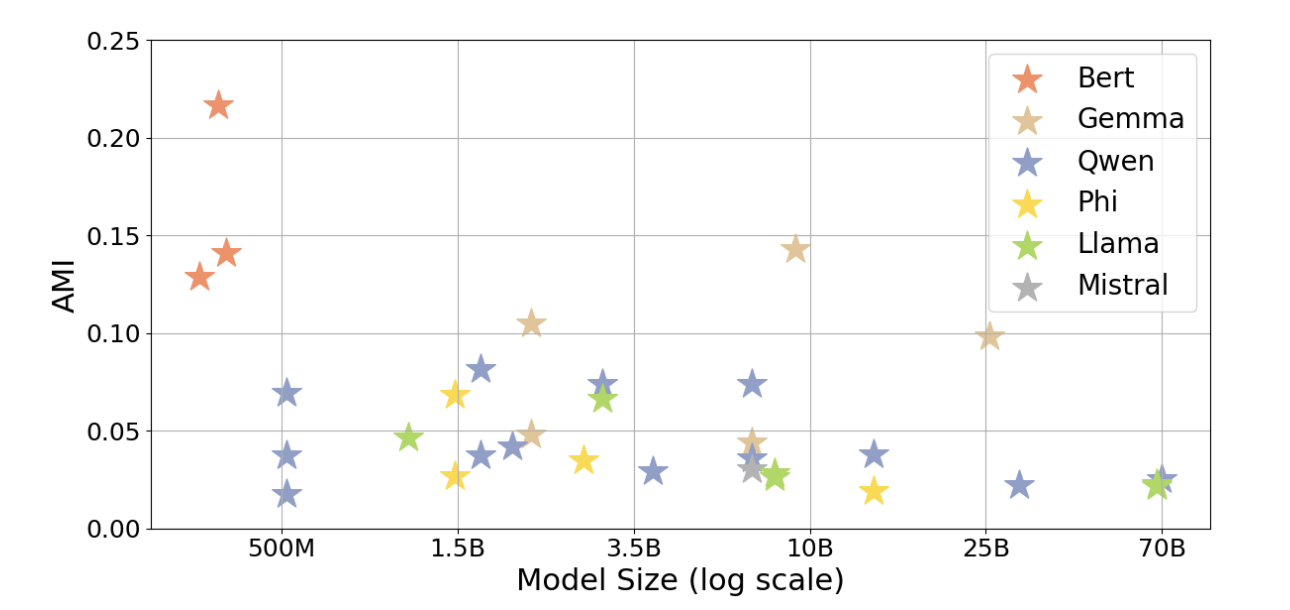
재미있는 결과는, 모델 사이즈에 상관없이 Decoder 기반 모델의 경우 AMI 값이 0.0~0.15 사이를 웃돌았다는 것이고, 모델 사이즈와 잘 군집화 하는것은 큰 영향이 없다는 것을 의미합니다. 반면 Encoder (BERT family) 모델의 경우 Decoder base 모델 대비 파라미터 사이즈는 매우 작으면서도 Decoder 모델들 대비 높은 AMI 지수를 보이는 것을 확인할 수 있습니다.
하지만 앞서 설명에서도 적었듯, AMI 지수가 1에 가까울 수록 두 군집이 유사하다고 판단할 수 있는데
모든 모델들이 0.25 미만의 점수 결과를 나타냈다는 것은 과연 LLM이 인간이 표현하는 카테고리와 유사한 정렬을 보이는것이 맞는것인지 의문이 들긴 하네요.. 🤔
[RQ2]
두 번째 실험입니다.
두 번째 실험은 결국 그렇게 표현한 LLM Representation 과 인간의 인지 구조가 정말 "구조적"으로 닮았는지를 확인합니다. 해당 내용을 확인하기 위해 본 실험에서는 같은 카테고리 (Human cognition으로 잘 정렬된 데이터셋에서 기반한)를 이용해 LLM이 Clustering 한 내용과 사람이 분류한 것을 바탕으로 구조가 유사한지를 확인합니다.
확인을 위해 평가 방법으로 Cosine Similarity와 Spearman's correlations를 사용했는데요, 왜 이 평가 방법을 사용했는지는 따로 설명되지 않아 아쉬움이 있었습니다.
실험 결과를 보면, LLM은 앞서 설명한 "전형성"이 적용되는 부분의 개념들이나 심리학적인 것이 반영되는 개념들의 경우를 잘 캐치하지 못한다는 것을 확인할 수 있습니다. 즉, Cosine similarity 나 상관계수를 확인해봤을 때 사람이 판단한 전형성을 가지고 있거나 심리학적인 개념이 들어가는 내용들은 구조가 멀게끔 측정되었다는 것이죠. (이것도 정확한 실험 내용은 없습니다만.. 😅)
또 재미있는 점은 BERT-large model이 다른 모델들에 대비했을 때 (Decoder based model) 더 강한 상관관계를 나타낸다는 점입니다.
[RQ3]
마지막으로는 위의 개념에서 설명한 목적함수 $\mathcal{L}$를 이용하여 LLM이 표현하는 Representatoin과 사람이 표현하는 Representation 사이에서의 Trade-off를 각자 계산합니다.
이 계산을 통해 표현(Compression)과 의미보존(Meaning) 사이에서의 전체적인 밸런스를 평가합니다.
실험 결과, LLM에서 유도된 클러스터들은 통계적으로 항상 더 최적화된 균형을 달성하는 결과를 확인할 수 있었고, 인간은 LLM 대비 더 풍부하고 미묘한 내용들을 포착하지만 통계적으로 본다면 덜 압축되어있고 정보구조가 더 퍼져있으며 중복이 되는 내용들도 존재한다는 점을 확인 할 수 있습니다.
Discussion & Conclusion
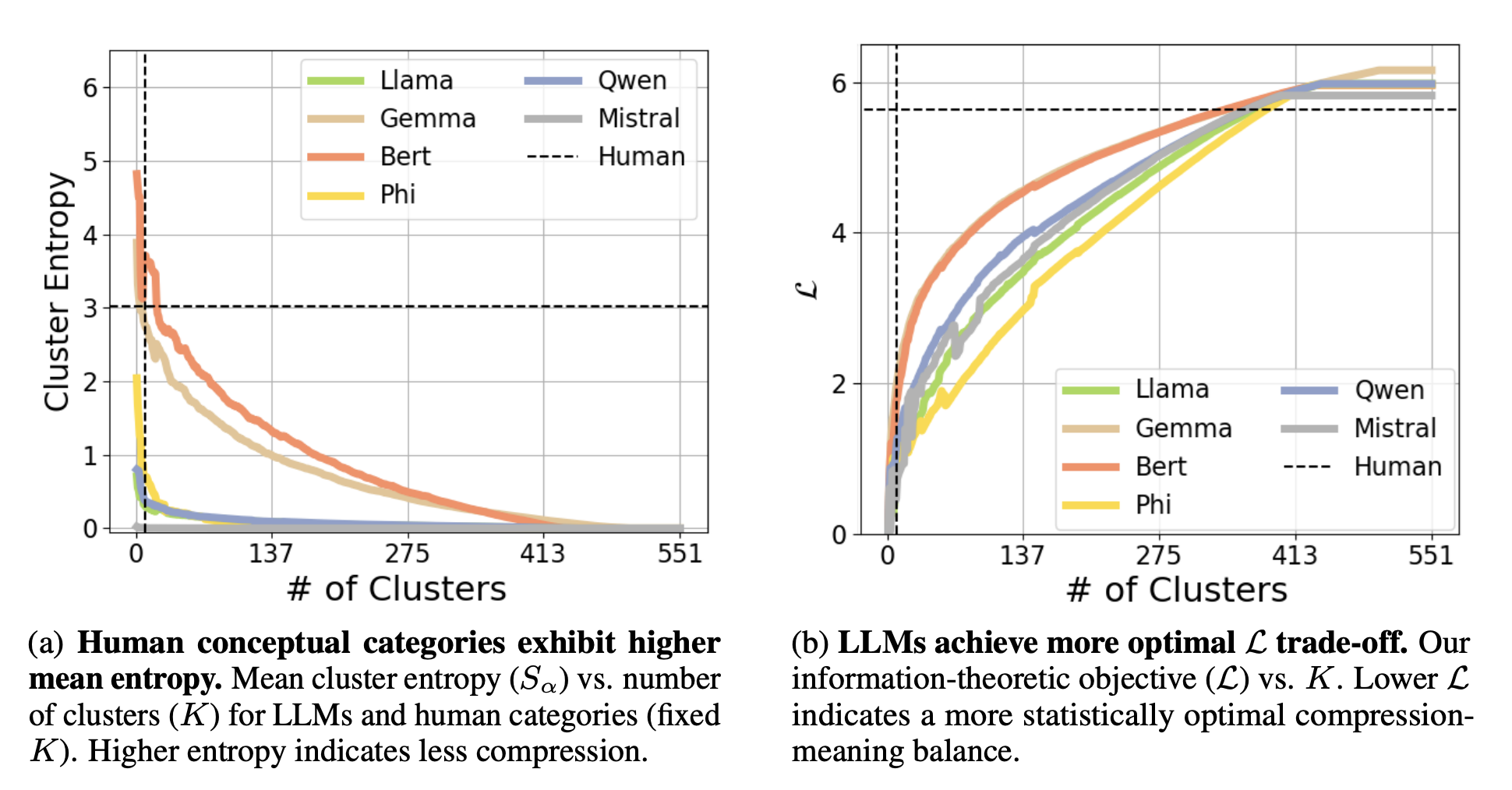
전체적인 실험 결과입니다.
그래프 상에서 점선은 Human Recognition에 기반한 결과를 의미합니다.
왼쪽 그래프에서 $Y$축은 Cluster Entropy를 의미합니다. 즉, 클러스터의 개수가 커질 수록 모델들은 그 복잡성이 안정화 되어있는 것을 확인할 수 있고 인간은 클러스터의 개수가 커진다고 해도 복잡도를 일정하게 유지하는 것을 확인할 수 있습니다.
오른쪽 그래프 역시 마찬가지로 클러스터의 개수가 적을수록 앞서 설정한 목적함수 $\mathcal{L}$이 사람 대비 모델이 더 작은 값을 나타내는 것을 확인할 수 있는데요, 작을 수록 Trade-off 관계를 효율적으로 설정한 것으로 판단하면 됩니다. 즉, 사람 대비 모델이 오히려 통계적으로 의미보존과 압축 사이에서 밸런스를 맞춘 Trade-off 관계를 갖고 있었다고 설명할 수 있습니다.
또한 주목할만한 점은, BERT와 같은 작은 Encoder 모델들이 특정 정렬과제에서 눈에 띄는 성능을 보이며, 모델의 아키텍쳐와 사전학습 목표가 모델의 사이즈보다 더 인간의 유사한 개념적 정보를 추상화하는 능력에 큰 영향을 미친다는 것을 시사합니다.
Limitations
좋은 접근의 논문이었지만, 실험 과정에서 아직은 몇 가지 제약이 있었는데요, 내용은 아래와 같습니다.

Additional
사람의 개념 형성과 모델의 표현 사이의 관련 논문이 있는 것 같아 함께 참조 걸어둡니다.
https://arxiv.org/abs/2506.23055
'AI (인공지능) Paper Review > NLP' 카테고리의 다른 글
| [BERT] Pre-training of Deep Bidirectional Transformers for Language Understanding 논문리뷰 (0) | 2024.05.12 |
|---|---|
| [Transformer] Attention is all you need 논문리뷰 (0) | 2024.03.02 |