

MoE (Mixture of Expert) 기법을 Mistral 모델에 적용한 Mixtral 8*7B 모델을 소개한 논문입니다.
최근 MoE 기법이 대두됨과 동시에 Mixture of Expert 에 대한 게시물을 작성해보면서 함께 읽고 정리해보았습니다.
잘못 이해한 부분이 있다면 댓글을 통해 오류를 말씀해주시면 감사하겠습니다🤗
논문은 24년 1월 발표되었으며, 원문 링크는 아래에서 확인할 수 있습니다.
https://arxiv.org/abs/2401.04088
Mixtral of Experts
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router
arxiv.org
Abstract & Introduction
본 논문에서 제안된 Mixtral 8*7B 모델은 앞전 게시물을 통해 설명한 mixture of expert를 이용한 Language Model 입니다.
Mistral 모델 8개를 각각의 Expert로 이용하였기 때문에 Mistral 7B 모델과 같은 architecture로 구성되어 있습니다. (하지만 각 FFN은 각 expert를 의미하며 다르게 구성된 8개의 FFN block이 존재하게 됩니다.)
중심이 되는 개념은 "Router를 이용해 2개의 Expert를 선정하고 이를 통해 output을 도출해낸다" 입니다.
각 토큰들은 2개의 Expert들만 볼 수 있지만, 선택된 Expert들은 각 타임스텝마다 다를 수 있기 때문에 결론적으로 MoE 모델의 각 토큰들은 전체 47B개의 파라미터에만 접근할 수 있습니다. (7*8 = 56B가 아닌 이유 : 모델에서 특정 입력이 주어질 때 모든 파라미터를 사용하는 것이 아니라 필요한 일부만을 활성화하여 처리함 (두 Expert만이 토큰을 처리할 때 활성화되기 때문).) 게다가 오직 13B의 Active 파라미터만이 추론과정에서 사용되기 때문에 빠른 추론이 가능하다는 것이 특징입니다.
Mixtral of Expert모델은 32K 토큰으로 이루어진 Context size로 구성되어 있으며, 이 모델은 llama2 70B 모델, 그리고 GPT-3.5 모델 대비 모든 벤치마크 성능을 능가했다고 쓰여있습니다. 특히 llama2 70B 모델 대비 Mathematics, Code Generation, Multilingual 벤치마크에서 뛰어난 성능을 보였다고 합니다.
본 논문을 통해 공개된 모델은 두 가지 인데, 기본 MoE 모델과 MoE-Instruct 모델이 있습니다.
Instruct 모델의 경우 파인튜닝된 모델로, Chat model & Human 벤치마크에서 GPT-3.5 Turbo, Claude 2.1, Gemini Pro, Llama2 70B 모델의 성능을 능가합니다.
실제로 두 모델이 Apache 2.0 라이센스로 공개되어 있기 때문에 기회가 된다면 직접 테스트하고 사용해 볼 수 있습니다.
https://github.com/mistralai/mistral-src
GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.
Reference implementation of Mistral AI 7B v0.1 model. - mistralai/mistral-src
github.com

논문에서 소개하는 MoE layer의 로직은 간단히 보면 위 그림과 같습니다.
Input vector가 들어오게 되면 Router에 의해 8개의 Expert 중, 2개를 선정해 할당하고 weighted sum을 구해 output을 도출합니다.
Mixtral Model의 Expert는 Standard FFN으로 구성되어 있으며, Vanila transformer architecture를 따릅니다.
Architectural Details
앞서 Introduction에서도 소개했듯, Mixtral은 Transformer architecture에 기반하고 있습니다.
구성된 모델 파라미터는 아래와 같습니다.

Sparse Mixture of Experts (SMoE)
구체적인 Expert network의 로직은 아래와 같습니다.

위 계산식에서 $G(x)_i$는 i번째 expert를 위한 gating network의 n-dimensional output을 의미합니다.
$E_i(x)$는 i번째 expert network 자체를 의미합니다.
이 논문에서 제안하는 Sparse MoE의 개념은 gating vector가 sparse 하다면, gate zero를 가진 Expert의 output을 계산하지 않음으로서 적은 파라미터로 효율을 높이는 것입니다. 즉, 분리해서 필요한 부분만 쓰겠다는 뜻이죠.
$G(x)$를 구성하는데에는 다양한 방법이 있지만, 가장 쉬운 방법은 Linear layer의 top-k logit을 추출하여 Softmax를 취하는 것입니다.
아래 공식처럼 표현할 수 있습니다.
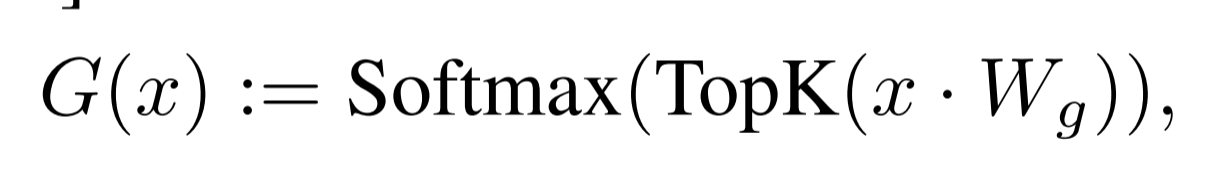
Softmax를 취했기 때문에, Top-k에 해당하는 로짓은 $l_i$를 반환하게 되고 아닌 경우 -∞를 반환하게 됩니다.
이렇게 뽑게 되는 k, 즉 logit의 개수는 expert가 토큰당 사용하는 수를 의미하며, 모델에서 일종의 hyper parameter를 담당하게 되고, 각 토큰 단위에서 사용되는 계산량을 조절합니다.
예를 들어, 만약 n이 증가하는 동안 k가 고정되어 있다면, 모델이 파라미터를 증가시키면서도 Computing 비용을 효과적으로 일정하게 유지할 수 있습니다.
총 파라미터는 n과 함께 증가하고, 활성 파라미터 수는 k에서 n까지 증가하게 됩니다.
본 연구에서는 MoE layer를 적용하여 Specialized Kernel 에서 고성능으로 Single GPU에 효과적으로 동작할 수 있음을 말하며, 동시에 Routing 기능을 이용한 모델 병렬화가 가능하다고 말합니다. 즉, GPU parallelism에도 적용이 가능하단 뜻이죠.
위에서 소개한 아주 쉬운 $G(x)$를 구성하는 방법으로 간단히 개념을 설명했습니다.
구체적으로 Mixtral 모델에서는 아래와 같은 로직을 사용합니다.

expert 2개를 선정해주어 Softmax를 태웠고, SwiGLU 를 사용하였습니다. (Swish + GLU : 일종의 Activation Function)
비슷한 로직으로 설명하면 GShard Architecture를 따르는데, GShard 또한 Transformer 아키텍쳐의 FFN 레이어를 MoE로 대체한 것이기 때문에 유사한 로직을 따르는 것이죠🙃
Results


Mixtral 모델의 성능 비교를 보면, 다음과 같이 주로 Llama 2 70B 짜리 모델과 비교를 하였습니다.
평가지표를 보면 파라미터 수 대비 Mixtral의 성능이 꽤 준수하게 뽑힌 것을 확인할 수 있으며, Math, Code와 같은 특정 태스크에서는 오히려 앞서는 성능을 보이기도 합니다.
Llama2 모델이 70B 파라미터를 갖는대비 Mixtral의 경우 Memory cost에서 총 47B 파라미터, Active Parameter의 경우는 13B이기 때문에 훨씬 적은 파라미터 사이즈 대비 큰 효율성을 갖는 것이죠.

다음과 같이 GPT-3.5 모델과 비교하기도 했습니다.

본 연구에서는, Mixtral model의 문맥처리 기능을 평가하기 위해 passkey retrieval 태스크 평가도 진행하였는데, (긴 프롬프트에 무작위로 삽입된 패스키를 검색하는 능력을 측정하는 태스크) 위 그림과 같이 context의 길이나 passkey의 위치 정보 없이 100%의 검색정확도로 판별해낸 것을 확인할 수 있습니다.
그 외에도 다양한 평가지표에서 우수한 성능을 보였다고도 합니다.🙃
본 논문은 정말 다양한 관점에서 많은 평가를 진행하였고,
또 기존에 머신러닝에서 쓰이던 MoE 관점을 Language Model에 적용하여 적은 파라미터 수 대비 좋은 효율을 뽑아냈다는 것이 특장점인 연구였습니다. LLM 연구에 있어 모델의 파라미터 사이즈는 최대한 줄여가면서도 높은 성능을 뽐낼 수 있도록 연구하는 것이 요즈음의 LLM연구 추세인데, 그에 걸맞는 아이디어가 아닐까 싶습니다.
MoE를 LLM에 적용하는 것이 또 연구 분야의 한 주제로 떠오르면서 MoE에 관한 다양한 논문들이 또 나오고 있으니 기회가 되면 나중에 추가적으로 논문리뷰를 더 진행해보도록 하겠습니다🤗