

RAG는 LLM 모델이 발전함에 있어서 꼭 알아야 할 필수 기능 중 하나입니다.
LLM 의 파라미터가 커지고 context window 사이즈가 점점 증가하게 되면서 RAG(Retrieval Augmented Generation) 또한 발전하고 있습니다.
Indexing & Retreival 기능을 이용해 학습되지 않은 내용에 대한 query의 답을 외부 Document를 통해 검색하여 답변 생성에 사용하는 것이죠. LLM의 규모가 커지면서 context window 사이즈가 커진다는 것은, 그만큼 참고할 Document의 사이즈도 커질 수 있다는 뜻이 됩니다. 즉, 기존보다 더 많은 Document들을 참고하며 User query에 대한 적절한 답변을 수행할 수 있습니다.
논문은 2020년 5월 발표되었으며,
원문 링크는 아래에서 확인할 수 있습니다.
오타나 오탈, 혹은 잘못된 부분이 있다면 언제든지 댓글로 정정 부분 말씀해주시면 감사하겠습니다🤗
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
Abstract
기존의 Pre-trained Language Model들은 Factual Knowledge를 매개변수에 저장하고 Downstream NLP task에 대하여 Fine-tuning을 수행하면서 좋은 결과를 얻어 왔다. 하지만 지식기반 정보들에 접근하고 이를 정확하게 조작하는 것은 여전히 어려운 문제이기 때문에 Knowledge-intensive task에 대해서는 Task specific architecture 보다 성능이 떨어진다는 단점이 존재 해 왔다.
따라서 이런 단점들을 보완하기 위해, RAG model이 제안되었으며, RAG 모델은 pre-trained parametric 과 non-parametric momery를 결합하여 언어 생성에 사용한다.
RAG에서 제안된 pre-trained parametric model은 seq2seq 모델을 이용하며 non-parametric memory는 Wikipedia의 dense vector들과 pre-trained neural retriever를 사용한다.
모델에 관하여 더 자세한 내용들은 method 챕터에서 다루도록 하고,
본 모델은
- QA Task
- Outperforming parametric seq2seq models
- Task-specific retrieve-and-extract architectures
에서 SOTA (State of the Art)를 달성했다고 한다. 즉 위의 Task들에 특화된 모델이라고 생각하면 좋다.
또 추가로, RAG model의 경우 기존의 SOTA를 달성 했던 parametric-only based seq2seq 모델에 비해 언어 생성 task에서 보다 더 구체적이고 다양하며 사실적인 언어를 구현한다는 사실을 확인할 수 있다고 한다.
Introduction
기존의 모델들은 메모리를 쉽게 확장하거나 수정할 수 없다는 단점이 존재했고, 따라서 Hallucination (환각) 현상이 생기기 쉬웠다. 하지만 Parametric memory와 Non-parametric memory (검색 기반 memory)를 합침으로써 RAG 모델은 지식확장 및 검색이 가능해지고 또한 접근한 지식 정보에 대한 검토 및 해석이 가능해진다.
RAG 모델을 통해 잠재적 문서 (Latent Documents)를 상위 K 근사치로 마진화 한다. 이는 출력 당 기준으로 수행 될 수 있으며 (동일한 문서가 모든 토큰에 대한 역할을 한다고 가정), 또는 토큰 당 기준으로 수행된다. (다른 문서가 서로 다른 토큰에 대한 역할을 한다.)
T5, BART, RAG와 같은 모델들은 seq2seq task에 의해 파인튜닝 될 수 있으며 Retriever와 Generator는 함께 공동으로 학습된다.
특정 Task들(사람들이 외부 지식 소스를 가져오는 방법에 대해 추론하지 못하는 부분)에서 non-parametric memory에 대해 발전시키고자 하는 많은 논문들이 제안되어 왔었지만, parametric & non-parametric memory를 함께 사용하고 pre-train 매커니즘을 도입하면서 기존과는 달리 지식 접근에 대한 능력을 훈련시킬 수 있다는 것이 가장 큰 강점이다.
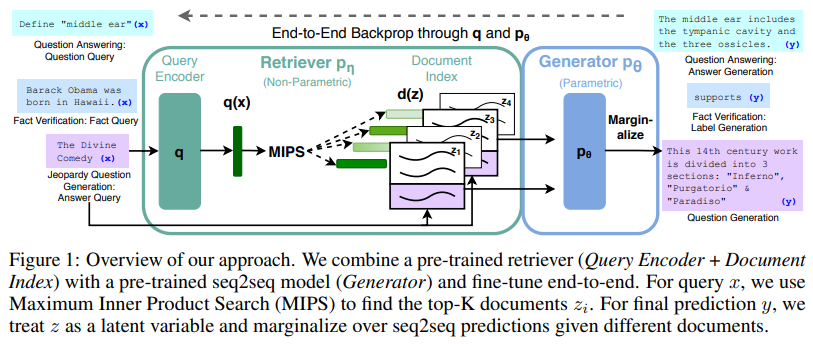
Method
RAG 모델은 input sequence $x$와 retrieve text document $z$를 이용하여 target sequence인 $y$를 생성한다. 단순하게 수식으로 나타내면 조건부 확률로 표현할 수 있는데, Retriever에서는 k근사치를 이용한 값으로 $q$ query랑 비슷한 분포를 parameter에 기반한 조건부 확률에 의해 제공하게 되고 Generator에서는 $\theta$에 의해 previous token($y_i-1$)과 original input $x$, retrieved passage $z$를 기반으로 current token을 생성해낸다.
RAG 모델은 크게 두 가지로 나뉘는데, 쉽게 정리하면,
RAG-Sequence Model : 각 Target token을 예측하기 위해 Same Document를 사용
RAG-Token Model : 각 Target token을 예측하기 위해 다른 Document 사용
이라고 생각하면 된다.
또한 마지막으로 RAG 가 대상 클래스를 길이가 하나인 대상 시퀀스로 간주함으로써 시퀀스 분류 작업에 사용될 수 있다는 점에 주목하였으며, 이 경우 RAG-Sequence와 RAG-Token은 동등하다.
- Retriever : DPR
Retriever는 DPR 모델을 기반으로 구성되었으며, DPR모델은 bi-encoder architecture를 띄고 있다. 따라서 이를 수식으로 나타내면 다음과 같다.
$$P_n(z|x)\propto exp(d(z)^Tq(x))$$가 되고,
$d(z)$, $q(x)$ 는 BERT 모델을 의미한다. $d(z)$는 BERT 기반의 document encoder를 의미하고, $q(z)$는 BERT 기반의 query encoder를 통해 나온 query representation을 의미한다. 이를 K 근사치를 이용하여 가장 높은 근사치를 가진 상위 k-z 쌍을 계산해낸다.
k 근사치를 계산하는 방법은 최대 내적 검색(MIPS)를 이용하며, linear time 내 계산될 수 있다.
이러한 Pre-train된 bi-encoder DPR 모델을 이용해서 Retriever을 초기화하고 Document의 index를 설정하는 역할을 한다.
이렇게 계산된 Document index들은 모두 non-parametric memory로 간주된다.
- Generator : BART
Generator 부분은 어떠한 Encoder-Decoder를 사용해도 괜찮도록 모델링되어 있다. 본 모델에서는 BART-large 모델과 400M Parameter로 Pre-train된 seq2seq transformer 모델을 사용하였다. query input $x$와 retrieve content $z$를 결합하여 BART로부터 토큰을 생성하기 위해서, 두 $x, z$를 concatenate 하였고 BART 모델은 Denoising과 다른 다양한 nosing 함수를 사용하여 Pre-train 되어 있다. 또한 BART Generator의 매개변수 $\theta$는 매개변수 메모리(parametric memory)로 간주된다.
- Training
트레이닝을 진행할 때에는, 어떤 Document에서 검색을 수행해야 되는지에 대한 사전 정보를 주지 않고, finetuning 한 input/output 형태의 형태소쌍만 제공한다. 또한 Document Encoder부분은 고정한채로 query encoder BERT 모델과 BART generator 만 finetuning을 거쳐 학습을 진행하는 방식으로 학습된다.
결론적으로 RAG model은 BERT 모델을 이용하여 query, document에 대한 index를 의미하는 토큰들을 생성해내고 그 쌍을 계속 훈련데이터로 제공해주면서 최적의 검색 Document를 찾아 대답할 수 있도록 고안된 모델인 것 같다.
GPT-4-turbo, Google Gemini가 발표되고 multimodal을 지원하는 llm 모델들이 대거 등장하면서, 또 기존의 llm의 고질적인 문제들을 해결해 나가고자 하면서 이런 검색기능이나, API 기능 등 외부 지식 혹은 모듈들을 호출할 수 있는 기능의 중요성이 더욱 중요해지면서 RAG와 같은 모델의 중요성이 점차 커지고 있다고 느껴진다. 앞으로 이런 부분에 대한 고민들이 더 필요해지는 연구들이 많이 나와야 하지 않을까..!!
'AI (인공지능) Paper Review > Gen AI (Large Model)' 카테고리의 다른 글
| [Lost in the Middle] How Language Models Use Long Contexts 논문 리뷰 (0) | 2025.03.21 |
|---|---|
| [HyDE] Precise Zero-Shot Dense Retrieval without Relevance Labels 논문 리뷰 (0) | 2024.07.29 |
| [LoRA] Low-Rank Adaptation of Large Language Models 논문 리뷰 (4) | 2024.07.24 |
| [SMoE] Mixtral of Experts 논문 리뷰 (1) | 2024.04.28 |
| [Augmented LM] Augmented Language Models : a Survey 논문 리뷰 (1) | 2024.01.12 |