

RAG가 한창 유행일 당시 (지금도 여전히...)
Long Context 사이즈의 모델의 필요성이 대두되었고, 모델이 새로 개발됨에 따라 긴 길이의 Context를 수용할 수 있는 모델들이 등장하곤 했습니다. 위 논문은 긴 Context가 들어왔을 때 모델이 문맥의 앞, 뒤는 이해를 하지만 중간 내용은 소실할 수 있는 부분에 대해 다룬 논문입니다.
원문은 아래 링크에서 확인하실 수 있으며, 리뷰 내용에 잘못된 부분이나 오탈자가 있다면 언제든 댓글 달아주시길 바랍니다!🙌
https://arxiv.org/abs/2307.03172
Lost in the Middle: How Language Models Use Long Contexts
While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze the performance of language models on two tasks that require identifying relevant information in the
arxiv.org
Abstract
- Language Model이 관련 정보를 input context에서 가져오는 두 가지 태스크에 대해 연구함
- multi-document question answering
- key-value retrieval
- 긴 input context 안에서 답변에 관련한 정보를 어느 위치에 두느냐에 따라 성능이 상당히 저하되는 것을 확인
- input context 내에서 답변 관련 정보가 context의 앞 부분이나 끝 부분에 있다면 꽤 높은 성능의 결과를 보여주는 것을 확인할 수 있었고, 관련 정보가 context 중간에 위치할 수록 성능이 저하되는 것을 확인

Introduction
언어 모델이 시간이 흐름에 따라 다양한 성과를 보이고 발전하면서, LLM을 이용한 많은 DownStream Task 들이 진행되었습니다. LLM은 기존의 언어 모델과 달리 Prompting 기법을 통해 DownStream Task 들을 수행하곤 하는데요,
관련된 task를 찾아 llm 이 원하는 답변을 출력해내기 위해서는 Input context에 들어온 토큰 정보를 확인하여 어떤 DownStream Task 를 수행해야 할 지를 판단하고, 답변을 출력해냅니다.
근데 만약 긴 정보량의 문서를 다루거나 외부 정보를 이용해서 (RAG를 수행하는 것과 같은) 모델이 관련 정보를 인식하고 이에 대해 답변을 하기 위해서는 context window에 수 천개의 토큰이 입력될 것이고 그 안에서 필요한 정보를 찾아내기는 쉽지 않겠죠.
대부분의 언어 모델(Language Model)은 Transformer 구조로 되어 있으며 sequence 길이가 길어질수록 메모리 소요량과 계산량이 상당히 증가하게 됩니다. 그래서 대부분의 Transformer 구조의 언어 모델들은 상대적으로 작은 context window를 가지고 훈련되어 왔습니다. 또한 알고리즘을 이용해 기존보다 더 큰 context window를 가질 수 있게 되었는데요,
하지만 여전히 큰 extended-context 를 언어 모델이 어떻게 잘 적용해 사용할지는 불분명했습니다.
그래서 본 논문에서는 SOTA 오픈모델과 클로즈드모델 (OpenAI GPT, Anthropic Claude 와 같은) 모델을 비교하여 Context 사이즈와 relevant information의 위치에 따른 모델 성능에 관한 연구를 진행했습니다.
만약 context 내의 Long input을 잘 사용하는 모델이라면 relevant information 의 위치와 관계 없이 좋은 성능을 유지해야겠죠.
논문의 첫 번째 실험은 Mutli-document Question-Answering 에 관한 실험입니다.
Multi-document 내의 QA가 진행되기 위해선, 모델이 제공된 문서 중 적절한 정보를 찾아 주어진 질의에 대해 답해야 하죠.
여기서 본 논문은 크게 두 가지 실험을 진행했습니다.
- Input Context 내의 문서 개수를 조절 해 실험하기
- Input Context 내의 관련 정보의 순서를 Context Window 내에서 바꿔보기 (컨텍스트의 시작점, 중간점, 끝점에 위치시키기)
이 과정에서 본 연구에서는 Context내의 관련 정보의 위치가 모델 성능에 영향을 미친다는 점을 발견했으며, 현존 모델은 아직 Long input context에 대해서 뛰어난 정보 접근과 사용이 어렵다는 점을 시사합니다. 즉, input context를 제대로 사용하지 않으면 기존보다 더 긴 입력 텍스트를 처리할 수 있는 모델이더라도 큰 성능상 효과가 없는 것이죠.
정말 Lost in the middle 현상이 일어나는지 알기 위해 본 연구에서는 synthetic key-vlaue retrieval task를 통해 이를 실험합니다.
모델에게 정수 key-value쌍 (json)을 제공해서 언어모델의 실제 검색기능이 잘 동작하는지 확인하는 것이죠. 이 실험을 통해 특정 모델들에서는 key-value쌍을 명확히 검색해내는 것을 확인할 수 있었고 일부 특정 모델에서는 위의 U-shape 커브 처럼 Lost in the middle 현상이 발생하는 것을 확인할 수 있었습니다.
이런 현상을 이해하기 위해서, 모델 구조에 대해 좀 더 조사를 해 보았는데요.
- Encoder-Decoder Model 의 경우, input context 내에서 관련 정보의 위치 변화에 강하다는 특성이 있지만, 오직 훈련기간 내 sequence-length 내에서 이를 평가할 때만 해당됨을 확인할 수 있었습니다.
- Query-Aware Contextualization(문서나 key-value쌍 앞 뒤로 쿼리를 배치하는 경우)의 경우 synthetic key-value task에서 가장 훌륭한 성능을 보였지만 multi-documentQA에서 trend를 최소한만 변화시키는 것을 확인했습니다.
- Base Language Models 즉, 기본 언어 모델의 경우 관련 정보의 위치에 따라 그림과 같은 U자 커브형 결과물을 보여줌을 확인할 수 있었습니다.
위의 내용들에 대해, 어떻게 언어 모델이 input context를 사용하는지, 또 long context 모델에 대한 어떤 평가 프로토콜을 채택하면 좋을지 실험을 통해 알아보고자 합니다.
1. Multi-Document Question Answering
본 논문의 연구 목표 중 하나는 어떻게 언어 모델이 input context를 사용하는지 잘 이해하는 것 입니다.
multi-document question answering 태스크를 진행하기 위해서는 모델이 input context내에서 관련 정보를 얼마나 잘 찾아낼 수 있는지가 중요한 쟁점이 되겠죠.

Experimental Setup
먼저, multi-domain quesiton answering task를 진행하기 위해서 모델 input으로 질문(Quesiton)과 문서들을 제공합니다.
이 문서들은 정확한 답변을 위해 참고해야할 관련 정보가 들어있는 문서와 정답과 관련 없는 문서 k-1개 (총 문서 : k개) 로 이루어져 있습니다.
실험 데이터셋으로는 NaturalQuestions-Open 데이터를 사용했구요. historical queries 와 Wikipedia를 참조하여 답변한 human-annotated answer쌍으로 이루어져 있습니다. 정보가 있는 문서에 대해서는 NaturalQuestions annnotation의 답변을 포함하여 데이터를 구성하였고, 정보가 없어야 하는 k-1개의 문서에 대해서는 MS-MARCO 데이터셋으로 파인튜닝한 검색 시스템을 이용했습니다. most relevant query 에 대해서 어떠한 NaturalQuestions-annotated answer를 포함하지 않도록 말이죠.

문서의 순서를 조정하기 위해서, 실험에서는 정답이 포함되어 있는 문서의 위치를 Input Context내에서 순서를 변경하였습니다.
또한 input context의 길이를 조절하기 위해서 관련없는 문서의 검색 수를 늘리고, 줄여 실험하였습니다.
실습 환경은 "NEEDLE IN-A-HAYSTACK" 실험과 유사한 환경으로 셋업하였습니다.
모델은 Open 모델에서는 MPT-30B-IT 와 LongChat-13B 모델을, Closed 모델에서는 GPT-3.5-Turbo 모델 4K, 16K Context 사이즈의 두 가지 모델과, Claude-1.3 (100K) 모델을 사용했습니다.
Results and Discussion

본 연구에서는 관련 문서를 10, 20, 30개로 늘려가며 실험을 진행하였습니다. 위 그림은 각 10개의 문서, 20개의 문서, 30개의 문서를 추출해서 input context에 넣었을 때 정답 문서의 위치에 따른 Accuracy를 나타낸 그래프입니다.
세 경우 모두 공통적으로 정답 문서(정답과 관련한 힌트가 있는 문서)가 input context 내의 문서들 중 첫 번째에 위치해 있다면 가장 높은 정확도를 보이고 문서량이 많아질 수록 위에서 설명한 U-net 커브의 모양으로 정확도 결과가 나오는 것을 확인할 수 있습니다.
그래프 상으로 GPT-3.5-turbo 모델의 경우 20-30개의 문서로 실험을 했을 때 정답 문서가 input context 내에서 첫번째에 있다 중간에 갈 수록 크게는 20%정도 성능이 감소함을 확인할 수 있습니다. 실제로 제로샷 추론을 했을 때 (정답 문서를 넣어주지 않고 기본 파라미터 지식만으로 답변했을 때) 약 56.1% 성능의 정확도를 나타냈는데 별반 다른 성능을 보이지 않다는 것이죠.
이는 Context가 큰 모델이 Downstream Task를 수행할 때 모델의 전체 Context Window를 효율적으로 쓰지 못하고 있다는 점을 시사합니다. 또한 Context에 따른 모델 성능이 큰 영향이 없다고 판단되는 것이, 그래프를 보면 gpt-3.5-turbo-0613 모델과 gpt-3.5-turbo 16K 짜리 모델을 비교했을때 그래프 상으로 거의 같은 선을 차지하고 있는 것을 확인할 수 있죠.
2. How well can Language Models Retrieve from input contexts?
그럼 어떻게 하면 언어 모델이 input context로 부터 필요한 내용들을 잘 추출해 낼 수 있을까요?
본 연구에서, 추가로 언어 모델이 context window내에서 필요한 내용들을 검색할 수 있도록 synthetic key-value retrival task에 관한 testbed를 실시하였습니다.
Experimental Setup
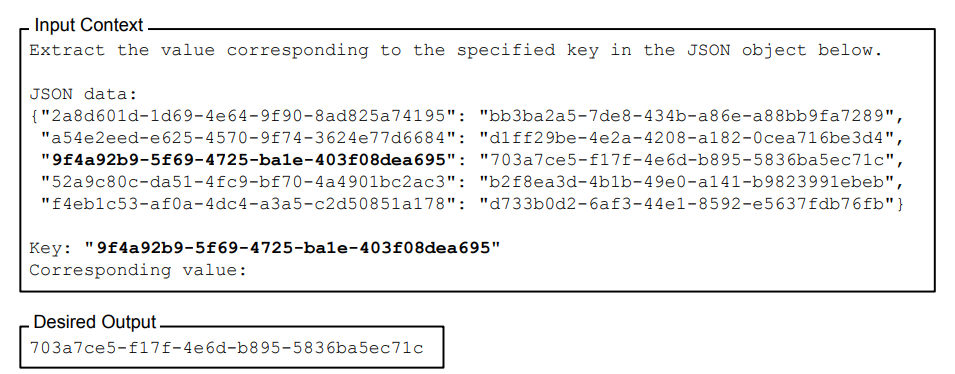
Synthetic Key-value retrieval task를 위해서, input은 string으로 직렬화 된 JSON을 key-value쌍으로 나타내어 준비합니다. 각 key, value값은 unique값이며 각 고유한 UUID로 생성되어 언어적 의미를 최소화합니다. 이 JSON Object와 Synthetic Key-value Retrieval 태스크를 이용하여 특정 key에 해당하는 값을 찾아 반환하는 것이 목표인 것이죠.
앞선 실험과 같이, 정답 key-value쌍이 있는 JSON 하나와 정답과 무관한 JSON k-1개의 쌍을 준비합니다.
Synthetic Key-value retrieval task의 목표는 "LITTLE RETRIEVAL TEST OF PAPAILIOPOULOS'와 유사합니다. Context Window내에서 자연어의 의미론적 특성을 최대한 제거하고(UUID 사용), 언어적 특징이 실험 결과에 영향을 줄 수 있는 잠재적 요인들을 모두 제거합니다.input context내의 position에 따른 성능 역시 확인하기 위해 input context내에서 key 값의 위치를 변화시키고 random key들을 추가하거나 제거해보면서 실험을 진행합니다.
Results and Discussion
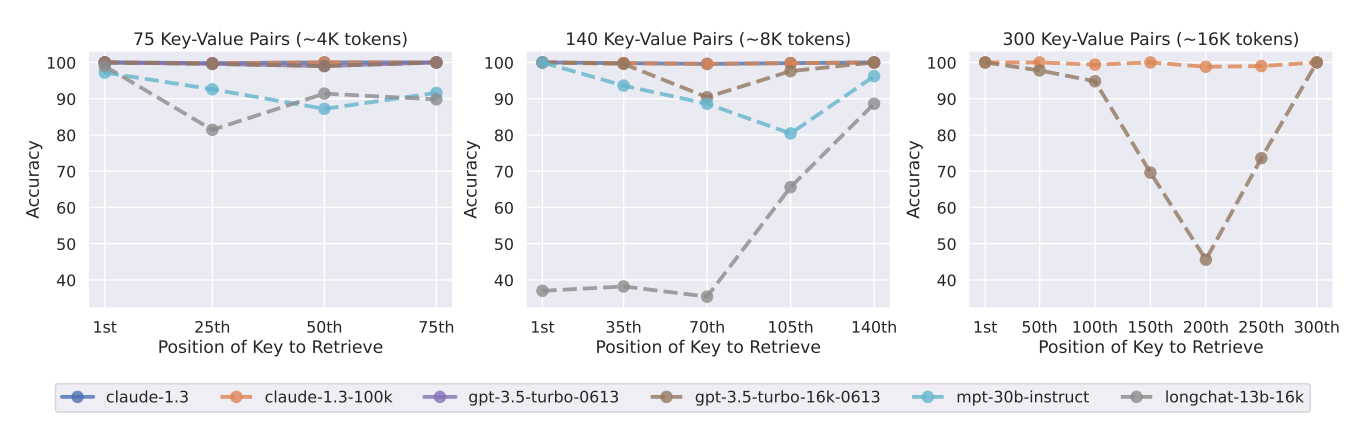
각각 75, 140, 300개의 key-value 쌍이 있는 context window에 대해서 실험을 진행하였으며,
앞선 실험과 마찬가지로 multi-document question answering 실험과 똑같이 모델을 설정하였습니다.
실험 결과를 보면, 클로드 모델의 경우 두 모델 모두 모든 Input context length 실험 결과에 있어서 거의 완벽한 성능을 보인 것을 확인할 수 있습니다. (해당 내용을 RAG 파이프라인 구축 시 모델 선정에 참고하면 좋을 것 같네요!)
하지만 클로드 모델을 제외하고 140, 300 개의 key-value쌍이 있는 실험에서 GPT 모델과 MPT 모델의 경우 이전의 실험과 같이 Input context의 중간 부분에서 lost in the middle 현상이 발생하는 것을 확인할 수 있습니다.
LongChat 모델의 경우 140 key-value pair 실험에서 또 다른 결과를 확인할 수 있었는데요,
Input context 내에서 정답 key-value쌍이 앞부분에 위치하면 LongChat모델의 경우 key값에 해당하는 value값을 찾아내는 것이 아닌 key 자체를 검색하는 코드를 생성해내는 경향이 있었다고 합니다.
3. Why are Language Models not Robust to Changes in the position of relevant information?
그렇다면 언어모델이 왜 relevant information의 input context내의 위치 변화에 강건하지 못할까요?
본 연구에서는 Decoder only(Autoregressive) 모델과 Encoder-Decoder 모델의 두 LM 관점에서 input context 내의 위치 변화에 따라 모델 성능이 영향을 받는 이유에 대해 알아보았습니다.

Transformer의 Encoder-Decoder 구조를 살펴보면 다음과 같이 구성되어 있죠?
Decoder Only Model은 각 시점에서 이전의 토큰에만 주의를 기울일 수 있습니다. 즉, 문맥을 파악할 때, 현재 단어를 예측하기 위해 이전 단어들만을 고려합니다.
반면, Encoder-Decoder 모델은 입력 시퀀스를 인코딩하여 고정된 크기의 벡터 표현으로 만들고,
이 벡터를 사용하여 출력 시퀀스를 디코딩합니다. 인코더는 입력 문장을 읽고, 디코더는 인코더가 생성한 표현을 바탕으로 target 문장을 생성합니다.
따라서 모델 구조적으로, Decoder-Only 모델은 각 시점에서 이전 토큰에만 주의를 기울일 수 있기 때문에 쿼리가 나중에 제공되는 경우 문맥을 효과적으로 활용하기 어렵습니다. 이는 쿼리 정보를 기반으로 전체 문맥을 재평가하는 능력이 부족함을 의미합니다.
Encoder-Decoder 모델은 양방향 인코딩을 통해 전체 문맥을 한 번에 처리할 수 있어 상대적으로 위치 변화에 강건하지만,
이 또한 훈련 시퀀스 길이를 초과하는 경우에는 성능 저하가 발생할 수 있습니다.
결론
언어모델에 더 긴 입력 맥락을 제공하는 것이 Downstream task를 수행하는 데 도움이 될 수 있지만, 모델이 추론해야 할 내용이 증가하여 정확도가 감소할 수 도 있다는 단점이 있습니다.
따라서 궁극적으로는 DownStream Task 의 특성에 따라 달라질 것이고 추가된 맥락의 한계 가치와 모델이 긴 입력 맥락을 효과적으로 사용할 수 있는 능력에 따라 달라질 것으로 보여집니다.
'AI (인공지능) Paper Review > Gen AI (Large Model)' 카테고리의 다른 글
| Google Prompt Engineering White Paper (0) | 2025.05.26 |
|---|---|
| [HyDE] Precise Zero-Shot Dense Retrieval without Relevance Labels 논문 리뷰 (0) | 2024.07.29 |
| [LoRA] Low-Rank Adaptation of Large Language Models 논문 리뷰 (4) | 2024.07.24 |
| [SMoE] Mixtral of Experts 논문 리뷰 (1) | 2024.04.28 |
| [Augmented LM] Augmented Language Models : a Survey 논문 리뷰 (1) | 2024.01.12 |