

이번 논문은 Advanced RAG 의 대표 기법 중 하나인 HyDE에 관한 논문입니다.
HyDE 는 Hypothetical Document Embeddings 의 약자로, 가상(가설)의 Document를 만들어 RAG Retrieval 성능을 올린 대표적 기법 중 하나입니다.
원문은 아래에서 확인하실 수 있으며 제가 논문을 해석하면서 틀린 부분이나 오류가 있다면 댓글 달아주시면 감사하겠습니다🤗
https://arxiv.org/abs/2212.10496
Precise Zero-Shot Dense Retrieval without Relevance Labels
While dense retrieval has been shown effective and efficient across tasks and languages, it remains difficult to create effective fully zero-shot dense retrieval systems when no relevance label is available. In this paper, we recognize the difficulty of ze
arxiv.org
요약
- Fully Zero-shot Dense Retrieval System
- User의 Query를 바탕으로 가상의 문서 (Hypothetical Document) 생성
- 위의 문서에 대한 임베딩을 생성하여 실제 문서 Collection (Vector DB)에서 유사한 문서 검색
- Advanced RAG
Introduction
HyDE(Hypothetical Document Embedding)은 Encoding Relevance 영역에서 Zero-shot learning의 성능을 올리기 위한 방법 입니다. 구체적으로 아래와 같은 과정을 거칩니다.
- User Query
- Instruction-following Language Model 을 통한 Hypothetical Document 생성
- (2)에서 생성한 Document을 Unsupervised constrastively 학습된 모델을 통해 Embedding
- (3)에서 Embedding 한 결과물은 Real Documents (실제 문서) 의 Embedding 공간과 유사한 Vector Space를 가르키게 됨. (Vector Similarity를 기반으로 함)
기존의 Dense Retrieval은 Semantic Embedding Similarity를 기반으로 한 Document Retrieving 을 진행하였습니다. 의미적으로 유사한 Embedding 값을 뽑아내는 것이었죠. Semantic Embedding Similarity를 기반으로 한 검색은 QA, Web search, Fact Verification 등 다양한 분야에서 우수한 성능향상을 이뤄냈지만 zero-shot dense retrieval 에 대해서는 여전히 난제였습니다.
기존에 query-docs와의 관련성을 나타내는 대규모 데이터셋(MS-MARCO)가 존재했지만, 이 데이터셋 마저도 Real-world 시나리오에서 모두 적용가능한 정도의 대용량 데이터셋은 아니었던 것이죠. 그런 데이터셋을 구축하기도 쉽지 않은일이구요.
그래서 본 논문에서는 real-world 시나리오에 모두 적용 가능한 fully zero-shot dense retrieval system을 제안합니다.
논문에서 제안하는 도입 개념이 GPT-1(Improving Language Understanding by Generatiwve pre-training) 논문과 비슷합니다. GPT-1에서도 모든 상황을 커버할 수 있을 만한 대규모 Labeled Dataset이 존재하지 않기 때문에 UnLabeled Data를 통해 Pre-training을 진행했었는데, HyDE 역시 대규모 데이터셋 없이도 효과적으로 동작할 수 있는 방법을 제시하네요.
현 NLP Task 에서, Document Level 에서의 모델 훈련은 text(chunk) Encoder의 Document-Document 사이의 유사도를 통한 대조학습을 통해 이루어졌습니다.
그리고 현존하는 LLM들은 Instruction Tuning을 통해 Un-seen instruction에 대해 zero-shot 일반화가 가능해지고 있죠.
그래서 이러한 관점들을 모아 HyDE를 제안하고 Dense Retrieval 을 아래 2가지 task에 대해 decompose합니다.
- Generative task performed by an Instruction-following Language Model
- Document-Document similarity task performed by a contrastive encoder

위 그림을 보면 알 수 있듯 GPT(Instruct LLM Model) 모델을 통해 Instruction-query 쌍을 input으로 넣고 Document들을 생성 한 후, 이에 대해 Contriever을 진행합니다.
# Contriever
: Dense Retrieval 을 위한 효율적인 모델. 대규모 문서 집합에서 관련 정보를 효율적으로 검색. 레이블이 없는 데이터로 학습되며, 특정 작업에 대한 fine-tuning없이도 효과적으로 동작
생성된 Hypothetical Document들은 실제로 존재하는 Document는 아니지만, Query-Answer 쌍으로 이루어진 input data에 관련한 Document를 생성할 수 있습니다.
다음으로 Contriever를 실행하기 전, 해당 Hypothetical Document 들을 Unsupervised Contrasive 로 학습한 Encoder를 통해 Embedding 공간에 벡터화 합니다. (Vector Database 구성)
또한 이 과정에서 본 논문은 Encoder의 Dense Bottleneck이 Embedding으로 부터 Hallucination 현상을 일부 필터링 할 수 있을것으로 기대합니다.
# Encoder Dense Bottleneck
: 입력 데이터를 더 작은 차원의 표현으로 변환하는 신경망 부분. 이 과정에서 데이터 압축 진행
HyDE를 도입하게 되면서 기존의 query-document의 유사도를 구하던 방식 대신에 Retrieval Task 는 NLU(Natural Language Understanding), NLG(Natural Language Generation) Task로 나누어집니다.
Method
Preliminaries(사전 학습)
$sim(q, d) = <enc_q{(q)}, enc_d{(d)}> = <V_q, V_d>$
기존의 query-document에 대한 유사도를 구하는 방식은 위의 공식과 같이 나타낼 수 있습니다.
Query 에 대한 Encoding 값 ($enc_q{(q)}$), Document에 대한 Encoding 값 ($enc_d{(d)}$)를 구해서 $Innder Product$. 즉, 내적을 통해 유사도를 구했었지요.
그리고 이 유사도를 기반으로 Query와 가장 연관된 Document들을 가져왔습니다.
이와 관한 RAG model을 학습할 때, Query를 Encoding 하기 위한 Query Encoder, Document를 Encoding하기 위한 Document Encoder, Relevance Judgements에 대한 명확한 Score가 없다면 학습도 비교적 어려웠던 것이죠.
HyDE
HyDE는 오직 Document Encoder (Embedding)만을 가지고 Document-Document간의 유사도를 비교합니다.
그리고 이는 Unsupervised contrastive Learning(비지도 대조학습)을 통해 쉽게 학습시킬 수 있습니다.
$f = enc_d = enc_{con}$
Document Encoder는 다음과 같이 Contrastive Learning을 거친 Encoder 모델로 나타낼 수 있습니다.
또한 모든 Document에 대해서 같은 Encoder를 사용하기 때문에 여러 Document Set에 대해서 공통으로 사용될 수 있는 범용성을 지니고 있습니다. 즉, 어떤 문서를 넣게 되던 같은 Encoder Model을 통해 Vector 공간내에 Embedding 되는 것이죠. (물론 문서에 따라 Embedding 값은 상이합니다.)
또한 Query Vector를 구성하기 위해서 Instruct LM 모델을 사용합니다.
Query와 INST(Instruction) 을 쌍으로 넣어 이를 바탕으로 Hypothetical Documents를 구축하는 것이죠.
Hypothetical Document는 실제 문서가 아니기 때문에 사실적 근거가 없을 가능성도 물론 존재합니다. 하지만 본 연구에서 바라는 바는 Hypothetical Document가 실제 문서에서 Relevance Pattern 을 포착하는 것 입니다. 이를 통해 관련성 패턴을 보다 일반화 하여 가져올 수 있기 때문입니다. (보다 더 Retrieval 성능이 향상되겠죠?)
Experiments
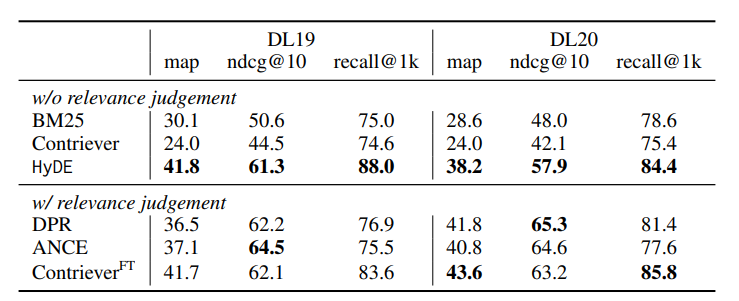
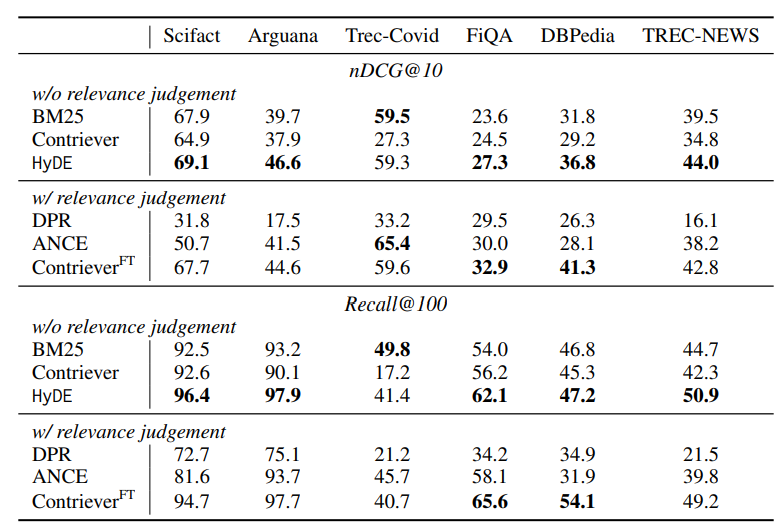
기존 Denser Retrieval 대비 relevance 성능입니다. 대다수의 Task에서 연관된 항목들을 잘 찾아오고 있는 것을 확인할 수 있습니다.
또한 본 연구에서는 HyDE 기법이 Fine-tuned model 대비 측면에서도 우수한 성능을 보이는 것을 입증했습니다.
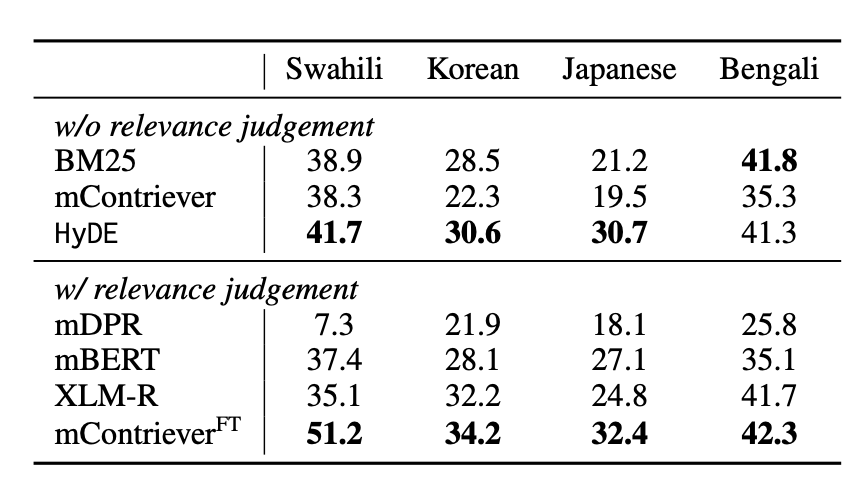
특히 Multilingual Retrieval에서 성능에 좀 특징적인 부분이 있습니다.
Small-sized contrastive encoder의 경우 언어의 수가 증가할 수록 Saturation(포화 상태)에 이르게 되었다고 합니다.
영어나 불어처럼 리소스가 풍부하지 않은 언어 (예를 들면 한국어, 일본어 등등)같은 경우에는 제대로 훈련되지 않을 가능성이 큰데요, 위 결과를 보면 mContriever(fine-tuned)를 통해 다국어 데이터셋에서 괜찮은 성능을 내 주고 있는 것을 확인할 수 있습니다.
HyDE와 함께 두 모델 모두 비슷한 Contrastive Encoder를 사용함에도 일정한 성능차이가 있는 것을 확인할 수 있습니다.
이는 Pre-train 과정과 Instruct Tuning 과정에서 충분히 훈련되지 않았기 때문이라고 고려하네요.
Code Practice
간단한 개념인 만큼, LangChain Docs 에 나와있는 내용을 통해 HyDE에 관하여 직접 실습해보았습니다.
1. HyDE (Hypothetical Document 생성)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications.
Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_no_context = prompt | llm | StrOutputParser()
answer = qa_no_context.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
print(answer)
다음과 같이 LangChain, LangGraph , LangServer, LangSmith 에 대한 관련 정보들을 넣고, System Prompt 를 작성한 후, qa_no_context = prompt | llm | StrOutputParser() 를 통해 User Query에 관한 Answer를 생성합니다.
from langchain_core.runnables import RunnablePassthrough
hyde_chain = RunnablePassthrough.assign(hypothetical_document=qa_no_context)
hyde_chain.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
이를 바탕으로 RunnablaPassthrough 를 통해 qa_no_context를 hypothetical_document로 설정하여 Hypothetical Document를 생성해 냅니다.
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.pydantic_v1 import BaseModel, Field
class Query(BaseModel):
answer: str = Field(
...,
description="Answer the user question as best you can. Answer as though you were writing a tutorial that addressed the user question.",
)
system = """You are an expert about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm_with_tools = llm.bind_tools([Query])
hyde_chain = prompt | llm_with_tools | PydanticToolsParser(tools=[Query])
hyde_chain.invoke(
{
"question": "how to use multi-modal models in a chain and turn chain into a rest api"
}
)
보다 구조화된 결과물을 뽑아내기 위해, Function Calling을 수행합니다.
2. Embedding & Retrieval
# Original Document load & Make a Vector DB
loader = DirectoryLoader('data/',glob="*.pdf",loader_cls=PyPDFLoader)
documents = loader.load()
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=20)
text_chunks = text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(documents=text_chunks,
embedding=OpenAIEmbeddings(),
persist_directory="data/vectorstore")
vectorstore.persist()
retriever = vectorstore.as_retriever(search_kwargs={'k':5})
우선 원문처럼 Original Vector DB와 비교하기 위해 Original Document가 존재하는 Vectorstore를 생성하고, Retriever를 제작해줍니다. (Chroma DB이용)
# retrievals
retrieval_chain = hyde_chain | retriever
retireved_docs = retrieval_chain.invoke({"question":question})
retireved_docs
# final RAG Chain
template = """Answer the following question based on the provided context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| ChatOpenAI(model='gpt-4o-mini',temperature=0)
| StrOutputParser()
)
print(final_rag_chain.invoke({"context":retireved_docs,"question":question}))
마지막으로 final RAG Chain 을 설정해주면, 관련된 문서 정보가 제대로 retrieval 되는 것을 확인할 수 있습니다.
참조
https://python.langchain.com/v0.1/docs/use_cases/query_analysis/techniques/hyde/
Hypothetical Document Embeddings | 🦜️🔗 LangChain
If we're working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model gener
python.langchain.com
https://www.sakunaharinda.xyz/ragatouille-book/3_HyDE.html
3. HyDE (Hypothetical Document Embeddings) — Ragatouille
3. HyDE (Hypothetical Document Embeddings) Instead of generating queries based on the original question, HyDE focuses on generating hypothetical docuemnts for a given query. The intution behind generating such hypothetical documents is their embedding vect
www.sakunaharinda.xyz
'AI (인공지능) Paper Review > Gen AI (Large Model)' 카테고리의 다른 글
| [Lost in the Middle] How Language Models Use Long Contexts 논문 리뷰 (0) | 2025.03.21 |
|---|---|
| [LoRA] Low-Rank Adaptation of Large Language Models 논문 리뷰 (4) | 2024.07.24 |
| [SMoE] Mixtral of Experts 논문 리뷰 (1) | 2024.04.28 |
| [Augmented LM] Augmented Language Models : a Survey 논문 리뷰 (1) | 2024.01.12 |
| [RAG] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 논문 리뷰 (1) | 2023.12.14 |