

LLM의 대표적인 PEFT 방법인 LoRA입니다.
기존의 Fine-tuning과는 달리 일부 parameter만 fine-tuning을 진행하여 FFT(Full Fine-Tuning) 대비 효율적인 파인튜닝을 위해 고안된 방법입니다.
Large Scale Model로 접어들면서 파라미터 수가 어마어마하게 커지게 되었고, 그만큼 fine-tuning을 진행하기 위해서 훨씬 더 많은 computing budget이 필요하게 되었죠, 이를 해결하기 위해 pre-train된 모델의 파라미터는 고정시키고 일부 파라미터만을 학습하는 방법입니다.
원문은 아래 링크에서 확인해 볼 수 있습니다.
논문을 리뷰하면서 오류나 제가 잘못 해석한 부분이 있다면 댓글 달아주시면 감사합니다. 🤗
https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
요약
- Efficiently fine-tuning technique
- Main Idea : Full Fine-tuning 대신, Pre-trained model의 일부 파라미터만을 학습시키는 방법(PEFT)
- Model Layer의 Weight를 Low-Rank 수준으로만 업데이트 하는 방법
Abstract
- Pre-trained Model을 Load하여 파라미터를 Freeze(고정) 시키고 각 Transformer Architecture에 Trainable Rank Decomposition Matrics를 주입한다. (Low Rank)
- 일부 파라미터 튜닝을 통해 Downstream Task에 대하여 훈련해야 하는 Parameter의 수를 확실하게 줄일 수 있음
Introduction
기존의 NLP Task의 경우, 여러 Downstream task에 해당하는 모델을 만들기 위해서는 하나의 큰 Pre-trained LM에 여러 개의 Downstream task에 따라 Adaption을 적용하는 방식의 파인튜닝을 진행해 왔었습니다. 하지만 앞서 말했듯, 대규모 언어 모델들이 등장하면서 엄청난 수의 파라미터를 한 번에 fine tuning하는 것은 아주.. 큰 회사라면 모르겠지만 거의 불가능한 일에 가까웠죠.
(예를 들어 GPT-3의 모델 파라미터 수가 약 175B개로 1750억개의 파라미터가 존재합니다.)
따라서 본 논문에서는 적은 수의 task-specific parameter에 대해서만 학습 결과를 저장하고 로드하고자 했습니다.
하지만 (당시) 현존하는 기술로는 모델의 depth 와 model 의 Usable sequence length를 줄일 수 없었고, 근본적으로 model quality와 model efficiency 사이에서 trade-off를 맞출 수 없었습니다.
본 연구는 2020년 12월에 발표된 "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning" 논문에서 착안하여, Over-Parameterized Model에는 Low Intrinsic Dimension이 존재하며 PCA와 같이 여러 차원의 파라미터들을 Low Intrinsic Dimension으로 차원을 축소시켜 기존의 Parameter보다 훨씬 낮은 차원의 부분 공간으로 모델을 표현할 수 있음을 말했습니다. 즉, Large Model이 겉보기에는 복잡하고 고차원적으로 보이지만 실제로는 훨씬 더 단순한 구조를 가지고 있을 수 있다는 뜻이죠.
그래서 연구에서는 Rank Decomposition Matrics를 적용하여 Dense Layer들을 바로 Optimizing하고 훈련할 수 있도록 했습니다.
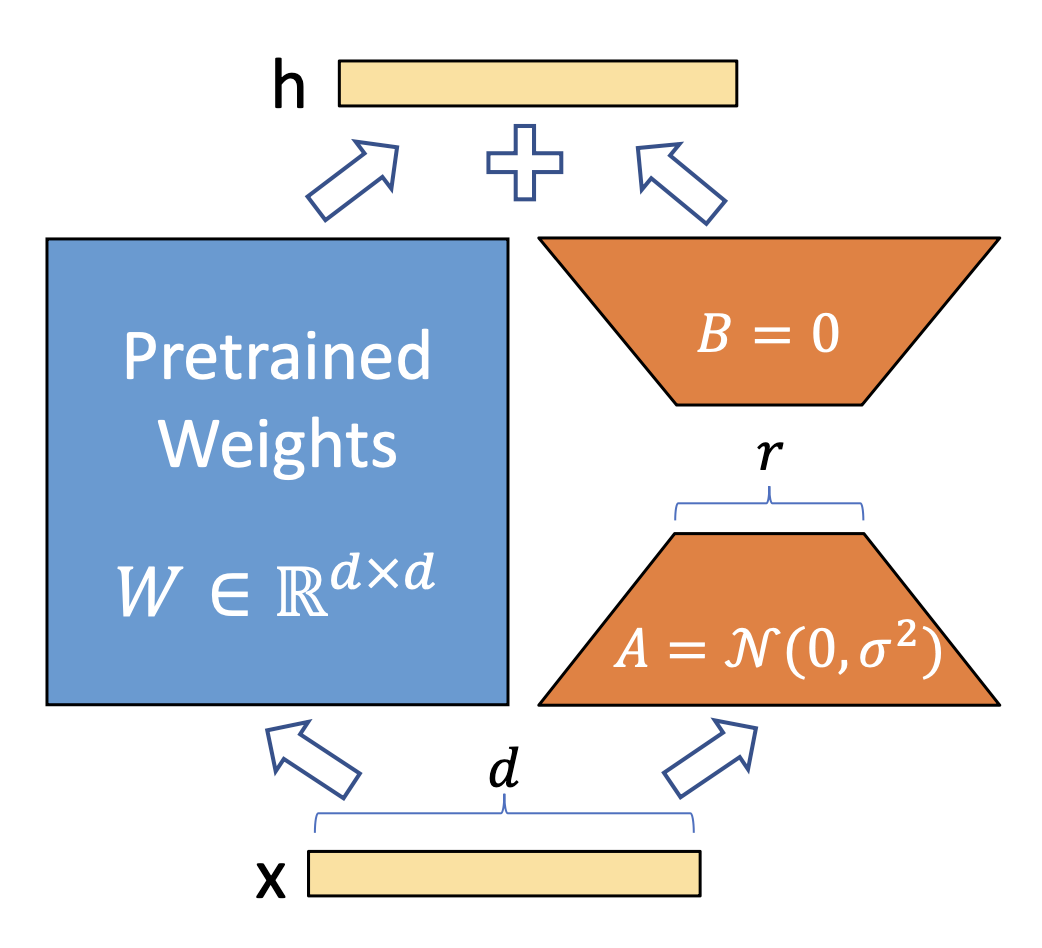
위 그림이 바로 LoRA Architecture 입니다.
원본 모델(Pre-trained Model)의 파라미터는 freeze하고 낮은 랭크 행렬인 A, B를 구하여 input X를 W weight, LoRA (B, A)를 통과하여 두 가지를 합쳐 최종 출력 h 를 생성해냅니다.
즉, 아주 낮은 rank의 행렬인 A, B를 Adapter 개념으로 적용하여 기존 Weight를 통과한 input과 Adapter를 통과한 input을 이용하여 output을 업데이트 (fine-tuning) 해 주는 것이죠.
직접적으로 pre-trianed 된 weight를 업데이트 하지 않기 때문에 튜닝에 있어 computing budget, memory 방면으로 훨씬 효율적임을 알 수 있습니다.
예를 들어, GPT-3 모델을 기준으로 전체 모델의 랭크(full rank)의 경우 12,288의 차원을 가지는데, LoRA를 이용하여 아주 작은 차원(r)의 Rank로 대체하여 업데이트가 가능하다는 것이 본 연구의 핵심입니다.
LoRA Process의 Key Advantages
- Pre-trained model은 각각 다른 task(downstream task)에 대한 작은 LoRA 모듈들을 서로 공유하고 사용할 수 있음. → Adapter를 갈아끼우는 형식으로 downstream task들에 대한 fine-tuning이 가능
- adaptive optimzier 보다 3배 더 낮은 Hardware barrier, More efficient 가 가능 → 대부분의 Parameter에 대해 gradient를 계산할 필요가 없거나 optimizer states를 유지하고 있기 때문
- 오직 low-rank matrics에 대해서만 optimize 진행
- Linear Design(선형 설계)를 통해 배포시 학습 가능한 행렬들을 고정된 가중치와 병합할 수 있도록 해줌. (fine-tuning 대비 추론 지연을 전혀 발생시키지 않음.)
Problem Statement
기존의 transformer based model들의 경우 다음과 같은 방식으로 parameter update가 진행됩니다.
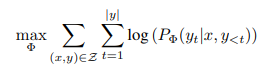
$\Phi$는 파라미터(weights)를 의미합니다.
수식에서 볼 수 있듯, 모든 Weight $\Phi$에 대한 확률 업데이트가 진행됩니다.
실제 task speicific fine-tuning은 아래와 같은 방식으로 gradient가 업데이트 됩니다.
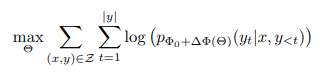
$\Phi_0$는 pre-trained된 모델의 weight를 의미합니다. 기존에 훈련된 weight 확률에 새로운 task에 대한 (x, y)의 파라미터 업데이트를 통해 모델 weight를 훈련하는 방식이죠. 그래서 기존의 fine-tuning의 경우 $\Delta\Phi$ 와 $\Phi_0$(Pre-trained weight)가 거의 같은 차원을 가지고 있었습니다. 즉, 앞서 말한 GPT-3의 경우 12,288개의 차원을 다 훈련시켜야 하는 것이었죠.
하지만 본 연구에서는 $\Delta\Phi(\Theta)$를 기존의 Pre-trained parameter보다 훨신 작은 수로 설정하여 일부 파라미터만 학습 할 수 있도록 고안하였습니다.
하지만 사실 이런 Adapter개념이 LoRA 논문에서 처음 도입된 것은 아닙니다.
기존에도 추가적인 Adapter를 학습하여 fine-tuning을 하려던 시도가 있었지만, Transformer 모델에 추가적인 층을 삽입하는 형태로 계산이 이루어지기 때문에 적은 매개변수를 사용하더라도 추론 시 시간 지연 증가 (Bottle neck현상)이 발생하여 계산 효율성을 잡지 못했습니다. 또한 모델 분산학습시에도 어댑터로 인한 추가적인 동기화 작업이 필요하기 때문에 오히려 좋은 방법은 아니었던 것이죠.
Method
본 연구에서는 LoRA의 방법을 두 가지 관점에서 소개합니다.
- Low-Rank-Parameterized Update Matrics
- Applying LoRA to Transformer
Low-Rank Parameterized Update Matrics
앞서 도입에서 말한 것 처럼, 본 연구에서는 모델을 표현할 수 있는 최소의 Intrinsic rank 의 범위가 존재한다고 가정하였습니다.
기존의 파라미터를 업데이트 하기 위해 아래 개념이 사용된다고 했습니다.

Pre-trained weight $W_0$이 존재하고 $\Delta{W}$ 를 추가적으로 학습하여 matrics sum 을 이용해 가중치 업데이트를 진행했었죠.
본 연구에서는 $\Delta{W}$ matrics를 $B$, $A$의 matrics로 분해해 적은수의 각 차원에 대한 업데이트를 진행하고 행렬곱과 덧셈을 통해 가중치를 업데이트 하는 방법을 제안합니다.
기존의 weights가 만약 $d*k$의 차원을 가지고 있다면, B를 $d*r$, A를 $r*k$의 차원으로 분해해 $BA$를 이용하여 업데이트가 가능합니다. 여기서 r = rank (Intrinsic Rank)를 의미하고요.
그래서 만약 작은 차원 (ex. r = 8)으로 설정한다면 $d * 8$, $8 * k$ 차원에 대한 연산만 진행해주면 되는 것이죠.
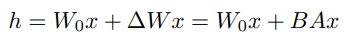
따라서 LoRA 구조를 보면 위와 같이 공식으로 나타낼 수 있습니다.
input $x$에 대해 Pretrained Weight를 거치고, Rank Decomposition을 진행한 $\Delta{W}$에 input $x$를 넣어 hidden state output을 도출해 내는 것입니다.
계산 과정에서 $\Delta{W_x}$에 대한 스케일링을 진행하기 위해 $\alpha$(Lora Alpha)를 사용합니다. $\frac{\alpha}{r}$를 이용해 Training 과정에서 Scaling을 진행합니다. Adam을 이용해서 Optimizing을 진행한다고 할 때 $\alpha$는 learning rate와 유사한 역할을 수행합니다. 처음 훈련을 진행할 때는 보통 $\alpha = r$을 같게 두고 진행하는 것이 일반적입니다.
또 다른 Downstream task에 대하여 fine-tuning을 진행할 때, 기존의 파인튜닝은 또 다른 task에 대해 다시 fine-tuning을 진행해주어야 했습니다. 하지만 LoRA가 $BA$를 이용하여 업데이트 후 결과값이 합쳐져 $h$로 표현되는 과정을 위에서 확인 했었죠. 하지만 LoRA에서는 최종 업데이트에서 $BA$값을 제거해주면 원본 weight를 보존할 수 있습니다. 따라서 원본 weight를 보존한 채로 $BA$(Adapter)만을 변경하여 여러 Downsteam task에 대한 fine-tuning이 가능합니다.
Applying LoRA to Transformer
기존의 Basic Transformer Architecture에는 4가지 weight metrics(Self-Attention Module 기준)가 존재합니다.
query, key, value, output에 대한 weight metrics가 존재하죠. Transformer Architecture에 LoRA 모듈을 적용하기 위해서 각각의 Weight에 대한 MLP Layer는 Freeze하고, LoRA Adapter를 적용합니다. 즉, Self-attention 모듈의 가중치 행렬만을 고려합니다.
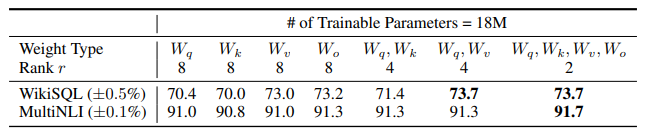
위의 표는 GPT-3 175B 모델에 대해 18M으로 Parameter budget을 설정한 실험 결과입니다.
한 가지 유형의 parameter에 rank decomposition을 적용했을 때 (각 $W_q, W_k, W_v, W_o$)
계산 결과는 $96(layer) * 1(# of weight type) * 12288(dimension of model) * 8(r) * 2(A, B 행렬)$ 로 계산되어 대략적으로 18M의 파라미터를 업데이트를 할 수 있게 되고, weight type의 수를 늘릴 수록 rank가 줄어들게 되는것을 확인할 수 있습니다. 즉, rank가 클수록 더 많은 표현력을 가지도록 학습할 수 있지만, 더 많은 파라미터를 사용할 수도 있다는 뜻이죠.
위 실험 결과의 경우, weight type을 4개 모두 선택하고 r size를 줄임으로써 오히려 더 좋은 성능을 보인 것을 확인할 수 있습니다. 즉, 단일 가중치에 높은 rank를 적용한 것 보다 여러 가중치에 낮은 rank를 적용한 것이 더 좋은 성능을 보였습니다.

이렇게 Transformer layer에 LoRA를 적용함으로써 얻는 가장 큰 효과는 바로 memory reduction과 storage usage에서의 효과입니다. LoRA의 경우 기존의 pre-trained parameter를 freeze하기 때문에 optimizing 과정에서 메모리를 사용할 일이 없어지는 것이죠. 그래서 175B의 GPT-3 모델 기준 VRAM 사용량을 1.5TB에서 350GB로 줄였다고 합니다. 이를 통해 GPU를 보다 적게 사용하고 I/O bottleneck 현상을 줄일 수 있습니다. 또한 LoRA Adapter를 변경하는 것으로 여러 task들 사이에서 switch가 가능하다는 것도 큰 장점입니다. 또한 막대한 양의 parameter 계산이 들어가지 않기 때문에 full fine-tuning 대비 훈련 속도도 약 25%정도 향상됐다고 하네요.
그럼에도 불구하고 LoRA 역시 제약이 존재합니다.
만약 추가적인 추론 지연을 제거하기 위해 A, B를 W에 흡수하기로 한 경우 다양한 task의 input들을 단일 forward pass에서 배치 처리하는 것이 어렵습니다. 일반적으로 배치처리는 동일한 연산을 여러 입력에 병렬로 적용하는데, LoRA를 이용하게 되면 각 입력(input)마다 다른 가중치가 필요할 수 있게 되는 것입니다. 다중 task 학습에서 단점이 존재하는 것이죠.
Empirical Experiments
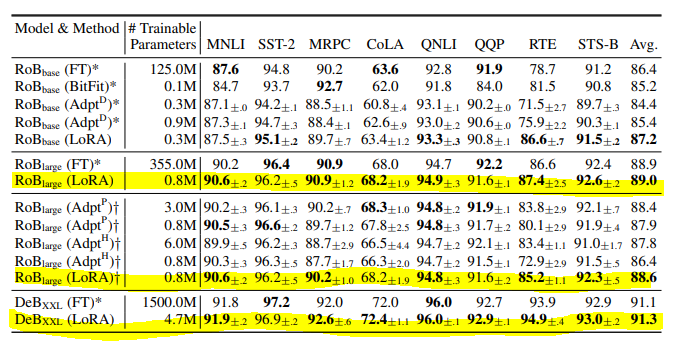
본 연구에서는 RoBERT 모델을 가지고 Fine-tuning, 기존의 Adapt 기법들, LoRA를 비교하였습니다.
위 표에서 볼 수 있듯이, RoBERT 모델과 DeBERT 모델 모두 여러 Task 벤치마크에서 Fine-tuning이나 기존의 Adapter tuning 대비 좋은 성능을 보인 것을 확인할 수 있습니다.

GPT-2를 Base로 한 모델에서는 다음과 같이 LoRA가 타 파인튜닝 대비 거의 모든 벤치마크에서 우수한 성능을 보였음을 확인할 수 있습니다.
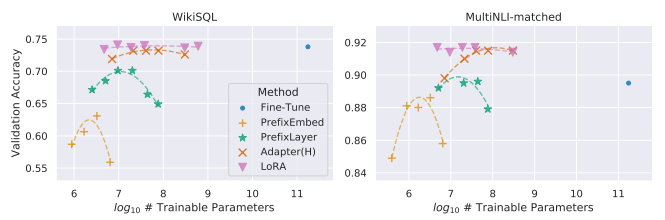
LoRA 에 대한 Stress Test를 진행하기 위해서, 본 연구에서는 GPT-3 Model을 사용하여 175B개의 파라미터를 사용하고 토큰수를 늘려 실험을 진행하였습니다. 두 벤치마크 결과 모두 Fine-Tuning 대비 유사하거나 더 나은 성능을 보이며, 다른 튜닝방법들의 경우 일정 토큰수 이상이 넘어가게 되면 오히려 성능이 하락하는 결과를 보여줬음에도 LoRA는 그렇지 않고 비교적 일정한 성능을 보이는 것을 확인할 수 있습니다.
'AI (인공지능) Paper Review > Gen AI (Large Model)' 카테고리의 다른 글
| [Lost in the Middle] How Language Models Use Long Contexts 논문 리뷰 (0) | 2025.03.21 |
|---|---|
| [HyDE] Precise Zero-Shot Dense Retrieval without Relevance Labels 논문 리뷰 (0) | 2024.07.29 |
| [SMoE] Mixtral of Experts 논문 리뷰 (1) | 2024.04.28 |
| [Augmented LM] Augmented Language Models : a Survey 논문 리뷰 (1) | 2024.01.12 |
| [RAG] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 논문 리뷰 (1) | 2023.12.14 |