

프롬프톤 회고.... 라고 쓰고 적는 개발 일지...
사실 프롬프톤이 끝난건 7월 중순이었는데 (ㅋㅋ..)
블로그를 한동안 못쓰기도 했었고 그 동안 또 배운것도 많고 많은 일들도 있었지만
그래도 더 늦어서 까먹어버리기 전에 회고록은 써야겠다 생각해서 뒤늦게... 기억을 더듬더듬 .. 더듬어 ... 작성함다🥲

어쩌다가?
서울프롬프톤은 서울디지털재단과 구글 클라우드에서 공동주관하였고,
나는 프로젝트형 부트캠프 팀원들과 함께 생성형 AI 관련 프로젝트를 막 시작하려던 참...
멘토님께서 개발기간이 비슷하니 한번 참여해보라고 권유해주셨다. (근데 사실 이거전에도 경기도에서 하는 생성형 AI 대회 참가하자고 했는데 아무도 신청안해서 못했음 ㅎ;)
우리가 프로젝트를 막 계획하고 시작한건 5월 초부터, 부캠이 끝나는 시기는 딱 6월이라 시간도 아주 적당했다.
어떤 프로젝트?
결과를 미리 스포하자면 우리는 프롬프톤에서 대상을 수상했다. (아직도 너무너무 영광입니다🥹)
그래서 기사도 떴다.
https://m.edaily.co.kr/News/Read?newsId=01617046638953864&mediaCodeNo=257
서울시 업무 혁신 AI 아이디어 경연…'2024 프롬프톤' 시상식 성료
서울시 업무를 혁신적으로 바꿀 인공지능(AI) 행정 서비스 아이디어를 발굴하는 ‘2024 서울 프롬프톤’가 지난 11일 에스플렉스센터에서 본선 경연 및 시상식을 열고 성공적으로 마무리됐다.(사
m.edaily.co.kr
하하하
우리는 음성기반 버스 예매 서비스를 웹앱 형태로 제작하였다.
맨 처음에 계획한건 어떤 서비스를 만들고싶다 보단 사실 취업에 도움이 될 수 있는 다양한 기술들을 적용해보고 싶었다.
그래서 LLM Agent 기능을 넣고 싶다는 막연한 아이디어에서 아이디어 회의를 시작했다. 정말 다양한 아이디어들이 오고갔고 이때 ChatDev, AutoGPT 등의 논문들을 엄청 찾아봤었는데 정해진 기간 안에 우리 현재 실력 수준으로는 (제일 중요한) 아마 시작만 창대하고 흐지부지되는 프로젝트가 될게 뻔했다.. (하하..) 그래서 사실 아이디어 선정과정에서도 난관이 있었다.
뭔가 가장 무난하게 접근이 되면서도 꽂혔던 아이디어가 바로 버스 예매 서비스였다.
대학시절부터 통학하거나 친구들을 만나기 위해 항상 고속버스로 왔다 갔다 했었는데 이때 느꼈던 고민들이 아이디어를 구체화 하고 해결하는 과정에서 큰 도움이 됐다.
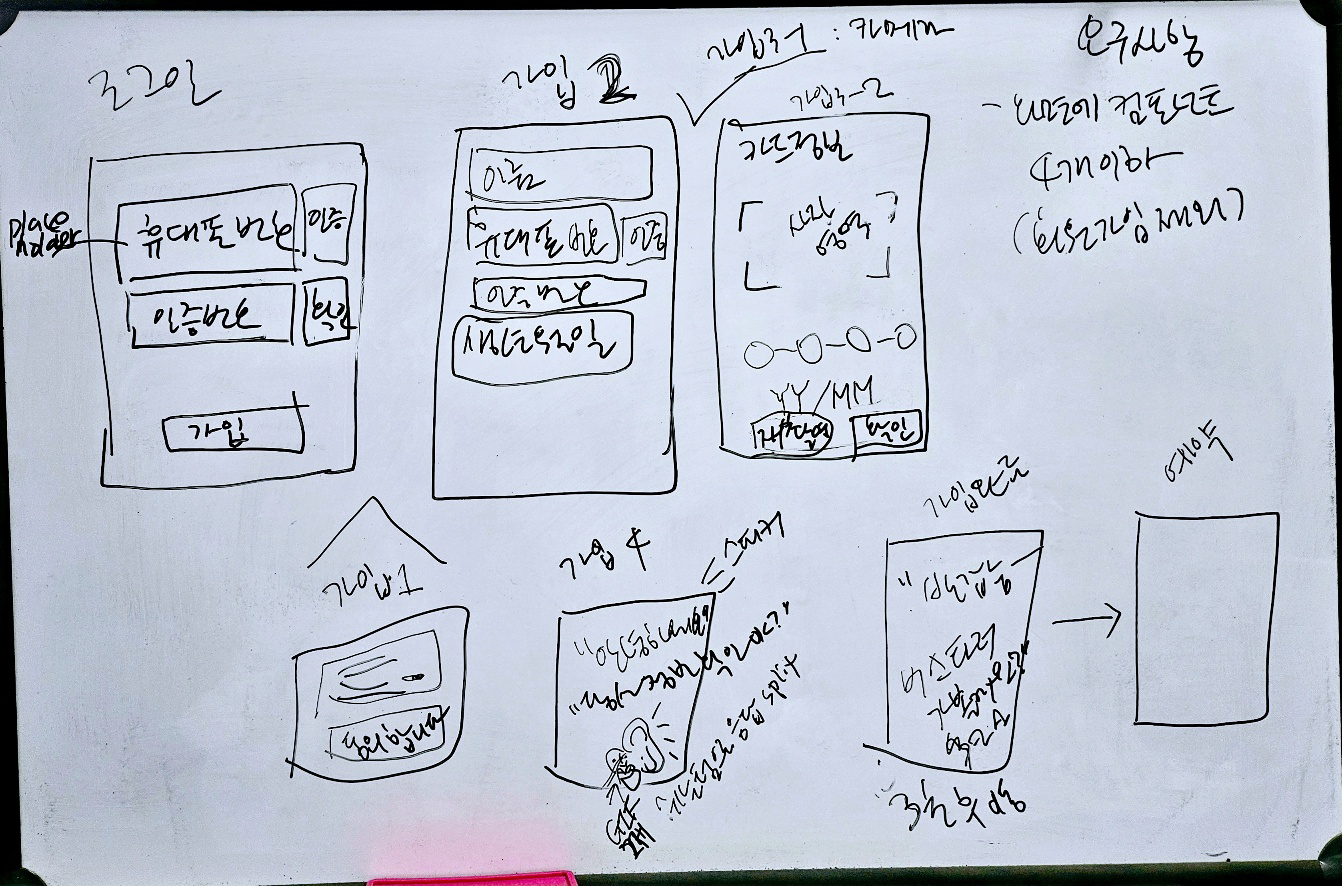
구체적으로 어떤 고민들이..?
서비스적 측면에서의 고민들
예매 시스템이 생각보다 그렇게 아주 간편하진 않다.
사실 우리 같은 젊은 층에게는 조금 거리가 먼 이야기일 수 있다. 하지만 나는 부모님 세대 분들이 예매와 탑승 과정에서 꽤 어려움을 겪는 경우를 많이 봤다.
(심지어 일주일 전쯤에도 본가에 내려가려고 버스 플랫폼 앞에서 기다리고 있는데, 어떤 아저씨가 예매 도대체 어떻게 하냐면서 갑자기 나보고 여쭤보셨다. 진짜 우리 서비스 실제로 출시해서 추천드리고 싶었음)
대표적인 예시들로
- 우선 앱 서비스가 그리 친절하지 않다.
- 앱과 키오스크로 예매 서비스를 대체하면서 어르신들이 점점 더 버스 예매를 어려워 했다.
- 고속, 시외버스는 오히려 고령 고객들이 주 타겟일 때도 있다.
- (이건 나의 주된 노선에만 해당 될 수 있다) 젊은 사람들이 미리 좌석들을 선점해서 이미 터미널 매표소에서 매표하려고 보면 매진인 경우가 허다하다.
보통은 많은 경우를 보면, 자녀분들께서 미리 결제를 해주시고 생성된 해당 QR 코드를 캡쳐하여 보내드리면서 대리 예매를 해드리는 경우들이 존재했다. 그런데 갑자기 버스 QR 단말기 오류가 있어서 기사님이 직접 검표를 해야하시는 상황이 되거나, 종종 스크린샷이 아닌 앱 화면을 기사님들이 요청하실때가 있는데, 그 경우 거의 대부분의 어르신들이 결국 승차를 거부당한다.
또, 내가 주로 탑승한 노선의 경우는
정말 경쟁이 치열하다..
오후 3-4시만 되어도 퇴근 이후 막차까지의 모든 배차가 매진인 경우가 허다하다.
사실 가끔 가는 노선이라면 미리미리 예매를 하지만, 매일 가는 노선이라면 미리 예매해두기가 솔직히 쉬운일은 아니다.
내 탑승 노선이 대학생, 직장인들이 많이 탑승해서 서울로 매일 출퇴근, 통근하는 분들이 많은 노선인데,
이걸 비집고 예매하기가.. 절대 쉬운일이 아닐거라고 생각한다. ... 그럼에도 고속 시외버스 이용 고객이라면! 탑승해야지!
그럼 어르신들이 배워서 직접 예매하시면 되지 않냐? 라고 반문할수도 있겠지만
부모님들께 직접 여쭤보니 사실 진짜 그분들이 직접 예매 하기를 바라느건 우리보다 본인들이셨다.
하지만 쉽게 이해되진 않고, 자식들에게 배우기도 미안하니 물어보지 못한다고 하셨다. (진짜 슬펐음 ㅠㅠ)
그래서 더더욱! 직관적인 서비스를 개발해서 직접 사용해서 예매하실 수 있도록 해드리고 싶었다.
그래서 처음 기획한 파이프라인은 아래와 같았다.

우리가 집중한 부분은 모든 결제, 조회, 구매 등등의 서비스를 음성으로 대체해서 복잡해보이는걸 다 없애자! 였다.
그래서 결제도 목소리 인증으로 대체해 무자각 인증처럼 사용자가 느껴지도록 구현해보려고 했다!!
기술적 부분에서의 고민들
프롬프톤에 참가하면서 가장 좋았던건, 개발비용으로 약 300만원 상당의 GCP 크레딧을 제공해준다!
(이건 프롬프트 테스트를 하면서 사용해봐도 좋고, 서비스를 배포해봐도 좋고, GCP에서 다양한 서비스들을 제공해서 정말 쓸만했다.
그리고 덕분에 GCP 관련 기술들을 몇개 찍먹해볼 수 있었음 ㅎㅎ)
우선 가장 큰 문제는
우리팀엔 백엔드 엔지니어와 서버 개발자가 없었다. (ㅋㅋ) 하지만 엄청난 실력의 프론트 엔지니어가 있었지
부트캠프에서 배운건 약 7일간의 FastAPI 였고, 시작하기 직전 마침 FastAPI 도서를 리뷰할 일이 있어 그걸 해보면서 체험해봤는데
딱 그정도로 배웠다.. ^^
그래서 이 때 Udemy 강의를 무진장 결제했었던 기억이 난다. (아직도 필요한 부분만 쏙쏙 골라서 듣고 있다)
(세일할때 결제했는데 거의 10만원 넘었음 ㅋㅋ)
나는 비전공자인데다 프로그래밍 경력이 1년도 채 되지 않았고, 파이썬 밖에 할줄 모르는데다 개발 지식도 전무하고 (Java랑 JS 를 구분도 못하는 수준이었음. 근데 어케어케 해서 정처기 필기 합격한 정도. 물론 지금은 조금 발전했습니다) 그저 파이썬 기반의 데이터분석이나 인공지능 모델 몇개 돌려만 볼 수 있는 수준이었다. DBA가 뭔지도 모르고 SQL 자격증 다 따니까 잠깐 공부한 정도.. 뭐 .. 그정도 수준이었다. (내가 생각해도 참..)
그나마 도움될만한건 최신 LLM 관련 논문들을 꽤 읽으려고 노력중이라 남들 보단 조금 기술을 들어봤다 정도, 인턴 경험을 통해 파이썬 디버깅과 (저는 아주 고전적으로 pdb를 쓴답니다 하하) 도커를 조금 안다 정도? 그게 우리의 기술적 첫 난관이었다. (...)
그럼에도 다행인건 우리 팀원들이 꽤 나처럼 욕심쟁이(?)들이었다 (ㅋㅋ)
그래서 뭐 어떻게... 그냥 GPT와 클로드에 의존하며 열심히 공부해가면서 완성시켰다.
약간 사담이었고,
진짜 기술적 문제는
1. 버스 예매 서비스를 제작하는데 적절한 API가 없었다.
티머니에서 API를 제공하고있긴 하지만, 우리가 실제로 서비스 구현에 필요한 API를 제공해주진 않았고 있는것 마저 횟수당 유료였다. (하지만 우리는 돈이 없지..)

출도착지에 대한 터미널 리스트나 노선 정보 조회 등은 있었지만,
실질적으로 예매하여 결제까지 이뤄질 수 있는 API는 존재하지 않았다. 그래서 우리는 Selenium을 통해 API를 만들기로 했다.
| router | function | step | api |
| 검색 /search |
search_destination_route() | 1 | 도착지 근처 터미널 검색(kakao api) /call_search_keyword |
| 2 | 검색된 도착 터미널과 실제 운행 터미널(DB) 비교 후 운행 터미널 기준으로 가장 가까운 도착 터미널 추출 /get_available_terminal_list |
||
| 3 | 도착 터미널에서 갈 수 있는 모든 출발 터미널 DB 검색 /call_target_terminal_list |
||
| 4 | 출발지 근처 터미널 검색(kakao api) /call_search_keyword |
||
| 5 | 검색된 출발 터미널과 실제 운행 터미널(DB) 비교 후 운행 터미널 기준으로 가장 가까운 출발 터미널 추출 /get_available_terminal_list |
||
| 6 | 출도착지 및 사용자의 출발 날짜/시간 정보로 검색 데이터 생성 /make_terminal_search |
||
| 예매 /reservation |
change_bus_date() | - | 조회 날짜 변경 /find_ticket_date_api |
| select_bus() | - | 선택한 버스 티켓 구매 /buy_bus_ticket_api |
그래서... 만들었음..!
(근데 너무 쪼개져있어서 나중에 LLM Function Calling 로직 짤 때 좀 고생좀 했다 ㅎㅎ ㅠ)
2. 목소리 인증 구현을 위한 모델 학습방법과 로직 구현의 어려움
우선.. 목소리 인증 구현을 위해 모델을 어떤식으로 학습해야 할 지 몰랐다.
그래서 우선 음성 관련 모델들 부터 찾아보기 시작했다. (Whisper, Wav2vec2.0 모델을 주로 확인하였음)
음성 모델에 대해 공부해본 건 처음이었지만, 흥미로운 부분들이 많았다. 음성 task는 약간 CNN과 NLP적 요소들이 섞여 있어서 복합적으로 재미 있었다고 할까?..
그래서 찾아본 Task들은 아래와 같다.
- Speaker Verification
- Speaker diarazation
- ASR (Automatic Speech Recognition) - STT
결론적으로 우리가 필요한건 Speaker verfication 태스크였고, 생각 보다 이 태스크에 대해 학습한 모델이나 연구가 없어서 당황했다.
(화자 분리는 엄청 많은데 정작 화자 인식은 없는 아이러니한 상황..)
우리는 한 화자에 대해 그 화자가 맞는지 아닌지 인식에 대한 태스크가 필요했기 때문에 Contrastive learning (대조학습)을 적용하기로 했다...!
그래서 데이터셋을 두고 Anchor와 같은 음성, 다른 음성을 두고 SSL 학습을 진행했다.
그리고 음성 모델의 Encoder 부분만 사용해서 화자별 음성에 대한 Embedding 값만을 비교하여 대조학습을 진행하기로 했기 때문에 보다 사용하기 쉬운 Wav2Vec 모델을 사용하였다.
(Whisper model 의 경우 Encoder-Decoder 구조이고, Wav2Vec2.0 모델의 경우 BERT처럼 Encoder만 있는 모델이었기 때문)
그리고 이 임베딩 값들을 어떻게 비교했냐면....
벡터 DB를 사용했다.
지금 생각해보면 RAG는 아니고 벡터 DB의 Search 기능을 이용해서 유사한 음성을 찾아오는 모델 구조를 만들고자 했다.
근데 우리가 사용해 본 Vector DB는 Chroma, FAISS 정도가 전부였다.
Chroma의 경우 이미지와 텍스트에 대한 임베딩을 지원하고 Docs에도 잘 설명되어 있지만
음성 분야는 해본 사람이 없었다는거 (...) 디코 Chroma DB 채널도 가입해서 열심히 찾아봤지만 할 수 없었음.
여러 Vector DB를 많이 뒤져보았지만 음성 로직에 대한 Vector DB를 사용한 사람이 거의 없었다. (진짜)
그러다 찾은 벡터 DB가 바로 Qdrant였다. 그리고 우리는 음성들에 대한 metadata 가 필요했기 때문에 (사용자 음성에 대한 메타데이터) 지금 생각해도 메타데이터로 검색이 가능한 Qdrant는 적절한 선택이었던 것 같다.
https://medium.com/@ashishabraham02/guide-to-using-qdrant-vector-database-for-audio-information-retrieval-33aa733494e7
Guide to using Qdrant Vector Database for Audio Information Retrieval
Navigating audio datasets with Qdrant
medium.com
요 게시물을 참고했던 것 같다.

3. Function Call을 해 본 적이 없었다.
아무도 function call을 해 본적이 없었다. 그래서 사실 Langchain 강의만 죽어라 파고 있었는데,
OpenAI API를 이용한다면 OpenAI에서 자체적으로 제공하는 Fucntion calling (Tool Calling) 부터 해봐야 실력이 늘거라고 멘토님께서 조언해주셨다. Tool Calling에 대한 용어가 LLM 플랫폼 별로 다 다른것도 이때 처음알았고 Calling 방법도 조금씩 차이가 났었다.
(이걸 wrapper 형태로 좀 편하게 제공해주는게 LangChain..)

사실 Function Calling 로직 구현할 때 애를 먹었던 건 API 가 쪼개져 있는데 꼬이지 않게 저걸 모듈화 해서 다시 함수를 만들어 적용하는데 어려움이 있었다. (우리가 API를 구매해서 쓰지 않고 공공 API 들을 엮고 Selenium을 통해 여러 개 만들었기 때문에..) 그래서 이거 처음 완성하고 너무 기뻐서 여러번 테스트 했던 기억이 ㅎㅎ
(근데 지금 LangGraph 가 나와서 이제는 이렇게 까지 안해도 된다는게 좀 허무하긴 함 ㅎㅎㅎㅎㅎ...)
4. 웹앱으로 음성 로직 처리하는 것이 처음이었다.
사실 제대로 개발을 해본 적 없는 나는 대부분이 처음이었지만 (ㅋㅋ..)
웹앱으로 음성 권한 동의를 받고 처리하는게 어려웠다. 그... 통신 부분이..
Socket 통신 이용해서 어찌어찌 구현은 한 것 같은데 음성 파일을 어떻게 관리할지가 계속 난관이었다.
이 때 제대로 배웠다고 생각한게 세션관리 방법이다.

우리는 User (회원 가입을 받았으니 ㅎㅎ) 별로 세션관리를 진행해서 임시 파일을 만들고 그 임시파일로 음성 비교 로직을 구현하고
사용자가 창을 닫거나 서비스를 종료하면 모두 사라지게끔 관리했다. 솔직히 세션.. 쿠키.. 가 뭔지도 몰랐던 나에게 처음엔 이해하기도 벅찼지만 일단.. 하라고 하니 해냈다 하하.
그리고 이때 경험을 토대로 다른 개발을 진행할때도
User별 데이터가 겹치지 않게 세션 관리를 해야 할 필요성을 지금은 누구보다 먼저 생각하게 된 것 같다.
5. 프롬프팅이 생각보다 쉽지 않았다.
사실 복잡하게 프롬프팅을 구현해 볼일이 없었다 보니 프롬프팅이 어려울거라곤 생각도 못했다. (ㅋㅋ)
맨 처음 OpenAI API를 사용할 때는 비교적 내가 거지같이(?) 말해도 아주 찰떡같이(?) 알아들어줬다.
하지만 Gemini로 모델을 변경하고 프롬프팅을 진행할때는 ... (왜 말을 안듣니)
그 과정에서 몇가지 팁을 알게 되었다.
- Gemini는 OpenAI 보다 샷을 더 넣어주어야 함 (최소 2개 이상)
- Gemini는 Output을 자꾸 md 형식으로 내뱉으려는 못된 습관(?)이 있다.
프롬프팅이 진짜 어렵다고 느낀 이유는
어떨땐 내가 원하는 결과물을 뱉어주고 코드를 수정하지 않았는데도 다른 결과물을 뱉어주기도 한다(!)
(그래서 어느 부분이 잘못됐는지를 디버깅 할 수가 없다.. 하지만 랭그래프를 쓴다면?)
6. 그 외 기타 고민들
그 외에도 기타 고민들이 많았다. GCP를 처음 사용해봐서 배포하는 법을 몰랐다.. (vm 만들어서 결국 그 안에서 띄웠다.)
ssl 설정을 못해서 chrome 설정으로 flag 무시를 해줘야지만 어플리케이션 동작이 가능했다. (.. 이제는 ssl 설정할 수 있습니다..!!)
이때는 도메인을 적용해야 한다 이런것도 몰랐고 사실 서비스 적인 측면에서 오류 터지는걸 복구하기에 급급했기 때문에...
이 외에도 여러 고민들이 있었지만..
결론

처음 생각했던 요구사항에서 기능들을 하나씩 줄여가긴 했지만
그래도 정해진 개발기간(?)안에 필수 기능들은 다 구현했다고 생각한다..!
GCP로 CI/CD 배포까지 직접 해볼 수 있었고 이 개발과정을 통해 이제는 파이썬 백엔드를 어느정도 구성할 수 있다.
그리고 쫌쫌따리로 DB 로 데이터 보는 법 가져오는법 등도 알고.. (SQL을 이제야 제대로 사용하는)
결과적으로도 우리의 고민들을 인정받는 것 같아 좋았다.
우리가 서비스를 기획하면서 클라이언트 입장에서 고려했던 점들을 심사위원분들이 바로 알아봐주셨다.
그리고 그 부분에 높은 점수를 부여해주셨다...!!
그리고 문제를 해결하는 방법에 있어 예전에는 뭐 학자처럼 개념부터 천천히... 익히겠다는 생각으로 공부를 해나가서 실제 코드에 적용되기까지에 꽤 시간이 걸렸는데, 이제는 Docs 보고 바로바로 적용하고 직접 경험해보면서 빠르게 깨닫는다. 그 후에 부족한 이론은 보완하는 방식으로 학습 방법을 바꾸게 됐다. 그래서 학습 속도가 상당히 빨라졌다. 개인적으로 너무 만족한다.
프로젝트가 좋은 결과를 수상했다고 해서 개인적으로 아주 만족스러운 프로젝트는 아니었다고 생각한다.
어느 프로젝트든 후회와 아쉬움이 남지만, 이번에도 마찬가지로 내가 조금만 더 많이 알고 잘 했더라면 부족한 기능들도 더 구현하고 고민했던 요구사항들을 적용해볼 수 있지 않았을까 하는 생각이 있다. (그리고 조금 더 열심히 기록해 둘 걸....)
그리고 이 프로젝트를 진행하면서 알게 된 좋은 분들이 있다.
아직도 도움을 많이 받고 있고 얌전히 그분들의 길을 따라가고 있다 ㅎㅎ
(그러다 보면 언젠간 같이 협업해 볼 수 있는 기회가 올지도..?!)
서울 프롬프톤 본선에 참여하면서 본선에 참여한 팀들의 다양한 결과물들을 관람할 수 있었다.
대부분의 참가자들이 RAG를 사용한 서비스개발 혹은 프롬프팅에 많이 공을 들인 모습들을 볼 수 있었는데 이 과정에서도 정말 많이 배웠다.
특히 한컴팀에서 시도한 다양한 한국어 프롬프트 템플릿들이 진짜 엄청나다고 느껴졌다.
발표에서 다양한 관점들을 고려해서 발표하신 분들도 너무너무 인상적이었다. 나중에 프로젝트 발표할일이 생기게 된다면 참고하게 될 것 같다 ㅎㅎ
PS
- 프로젝트 명은 GPT 가 추천해줬다. (ㅋㅋ) 나름 직관적이면서도 우리가 원하는 서비스 내용이 다 들어가 있어서 좋았음 ㅎㅎ
'후기 및 회고💦' 카테고리의 다른 글
| [가짜연구소] 10기 러너 시작! 🔥 (2) | 2025.03.07 |
|---|---|
| 조금 늦은 감이 있지만 2024년 회고록 (2) | 2025.02.02 |
| [GDG] Build with AI United 2024 후기 (0) | 2024.05.13 |
| 포스코 청년 IT 전문가 아카데미 8기 면접 후기 (10) | 2024.04.22 |
| [Upstage AI Lab] 3기 합격 + 등록 취소 후기 (0) | 2024.03.28 |